

Over the last few months I’ve been working on a project with the good folks at TCP — the latest stopover on my long, painful, only-debatably-successful journey to use technology to benefit health and healthcare in the world. I’ve written about this project a few times already, and I continue to be excited about the potential for SMART Health Cards and Links to get important information in front of the right people when they need it. In this post I’m going to try to push on that “in front of the right people” bit by going into nerdtastic detail about the SMART Health Viewer application we’ve been building. The code is all MIT-licensed, so I hope you’ll pick out anything useful for your own projects. Suit up, folks!
Disclaimer #1: I 100% do not speak for TCP — I’m just volunteering my time towards this work. Anything in the below that you find objectionable is on me and not them! 🙂
Disclaimer #2: This is all pretty techy and more than a bit dry; it probably won’t be your next favorite beach read. I’ve tried to keep it moving along, but my real objective is to just dump a ton of detail to help out other folks trying to build solid implementations. Next up will be some much more entertaining woodworking stuff, I promise!
A Quick Tour
While there are a few twists and turns under the covers, the app itself is really very simple:
- Read a SMART Health Card or Link using a barcode scanner, camera or copy/paste.
- View the health information, including (when available) provenance data.
- Save the information, using built-in copy/paste buttons or as a single document image.





The application can also run within the context of a SMART-on-FHIR enabled EHR system like Epic or Cerner. Additional features are available in this mode, for example:
- The current patient record can be searched for SMART QR codes (e.g., on a scanned insurance card).
- Rendered health information can be saved back into the patient record.
- Potential patient mismatches are flagged (e.g., if the current patient is Bob Smith but a COVID-19 vaccine record is for Jane Doe).



App Architecture
The viewer is a single page application built using React and Create-React-App (I swear CRA was basically deprecated ten minutes after I learned how to use it). Most of the interface uses Material UI, which is truly a blessing for folks like me that are design-impaired. The source is available on GitHub under an MIT license. The snippets in this post reference the version tag shutdownhook.2 so they’ll stay consistent even as the app evolves. So there you go, logistics out of the way!
An SPA running exclusively in the client browser offers two key benefits: first, it makes the app super-easy to host — any static web server (or even just an AWS bucket) can do the job. More importantly, it means that sensitive health information never leaves the client. This pretty dramatically reduces the exposure to privacy breaches, a Very Good thing.
The React component tree looks something like the below. We’ll examine each in detail, but for now think of this hierarchy as a roadmap to the application:
- OptionalFhir (holds the FHIR client if running in an EHR)
- App
- Tab Bar
- Selected Tab Content (one of the below)
- About (landing page)
- Scan (paste codes or scan with a handheld scanner)
- Photo (scan codes with a camera)
- Search (search for codes within the EHR)
- Data (SHX content, one of the below)
- UX to enter a SHL passcode
- Error text
- “Bundle” contents
- Bundle picker (only when > 1 bundle in SHX)
- ValidationInfo (provenance data)
- WrongPatientWarning (if in EHR and patient mismatch)
- Type-specific rendering (one of the below)
- Coverage (digital insurance card)
- Patient Summary (IPS)
- ImmunizationHistory (COVID-19 or general immunization record)
- Save to File / EHR buttons
- Selected Tab Content (one of the below)
- Tab Bar
- App
Build and Run
The only prerequisites to build the app are node, npm and git (stuff you probably already have anyways). Running in development mode is super-easy and hot-reloads as you edit:
git clone https://github.com/the-commons-project/shc-web-reader.git
cd shc-web-reader
git checkout shutdownhook.2
HTTPS=true && npm start
(Note that if you want to actually edit the code for real, add -b new_branch_name to that checkout command to start a branch).
The app will start up with a self-signed certificate (that you’ll have to approve) at https://localhost:3000/. If you have a SMART COVID vaccine card, scan it by clicking the “Take Photo” tab and holding it up to your camera. Or use the “Scan Card” tab and paste in the contents of a demo patient summary or insurance card. Pretty neat!
To deploy a version of the site, just run a build with npm run build, then copy the entirety of the “build” directory to any static web server. I use an Azure blob container for live testing, and keep it up to date using AzCopy like this (remember to azcopy login first!):
azcopy sync ./build 'https://shcwork.blob.core.windows.net/$web' --recursive
Run in EHR Context
A provider using the viewer may run it as a “SMART on FHIR Provider Launch” application. You can read a ton about provider launch apps elsewhere on my blog, but in a nutshell it means that the app runs in an iframe (or similar) within the EHR interface, inheriting its user and patient context. The embedded app is granted authorization to make read and write calls against data in the EHR on behalf of the logged in user. It’s a nice setup, albeit with some pretty inconsistent implementations.

In any case, you can try this out by running the viewer in the SMART Launcher, which simulates an EHR and provides some test data. On the page, make sure “Simulate launch within the EHR UI” is checked, enter https://localhost:3000/launch.html?client=abc into the “App’s Launch URL” box, and click the “Launch” button. You’ll be asked to “sign in” as a provider, select a patient, and then you’ll be right back in our familiar viewer interface — surrounded by EHR goodness and with a few new options available.
A key goal with EHR integration was to make it as invisible as possible (for developers). This is accomplished by the OptionalFhir component, which sits at the very top of our React hierarchy. The component examines the URL for the telltale signs of an EHR launch and, if present, kicks off the authorization process to end up with a FHIR client object. This client is tucked into state, and made available to any component with a React Context.
With this in place, any component can test for the presence of the FHIR object — meaning that we’re in EHR context — to enable relevant EHR features. For example, you can see this at work in the App component where we decide whether to show the “Search Record” tab. Of course, the same object can be used to actually read and write data, e.g., as we do in the Data component when saving a rendered image into the patient record.
Quick note: this FHIR dance was heavily informed by reading the code at https://github.com/zeevo/react-fhirclient … thanks Shane!
Top-Level App Layout & Config
The code starts to look like a typical web app in App.js. A MUI Tabs component handles top-level navigation between the content panels swapped into the next div: an about page, controls for capturing data, and one for displaying it. At the bottom is an optional footer specific to TCP, since we’ll be hosting a version of the app for use in the real world.
If there’s a SHX to display, it’s held in React state as scannedSHX. The Scan, Photo and Search components call back up to the App component using the viewData function to set it, and it’s pushed down to the Data component for rendering.
You’ll also see a bunch of config calls in this code (and throughout the project). Defaults are in (duh) defaults.js — domain-based overrides layer on top of a base set of options. Any config value can also be overridden in the query string (a common use for this last is “initialTab” which can be used to drop the user directly onto one of the scanning modes rather than starting with About).
Once a SHX has been scanned, control passes to the Data tab. Gross parsing errors can show up here, or a request for a passcode if needed. More typically, the data will be parsed and result in one or more FHIR “bundles” — collections of signed or unsigned FHIR resources that work together. If multiple bundles are present, a dropdown allows the user to select between them.
Finally, the selected bundle is rendered by a type-specific component. From here the user can interact with the data or select one of the scanning tabs to read another SHX.
Scanning Stuff: Scanners and Cameras
Scanning with a handheld scanner (like this one I use) isn’t particularly interesting — scanners just send keystrokes, so really you just need a textbox. Just remember to set the focus correctly and auto-submit if the user hits (or the scanner sends) a “return” at the end of the code. A bonus of the textbox is that copy/pasting codes is super-handy during development.
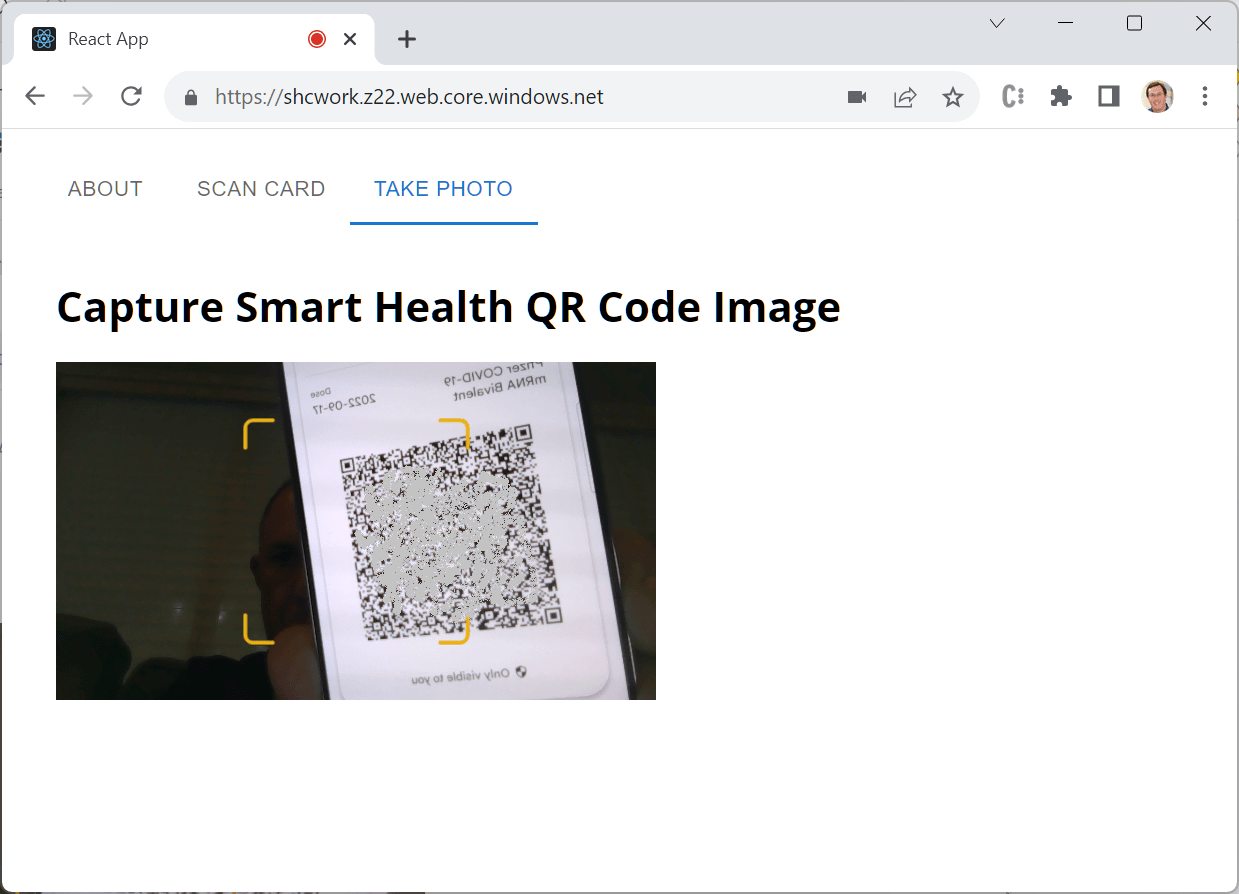
Scanning with a camera is much more interesting. We use qr-scanner, a solid and reliable module for picking barcodes out of camera feeds or static images. In its simplest form, you just instantiate the module, call start, and wait for it to find a QR code. Ah, but of course it’s never quite that easy.
First of all, we may not be able to instantiate a camera at all. Remember that the viewer is built to be embedded with an EHR, which often happens within an iframe that is subject to a number of security restrictions. One of these (unless explicitly permitted with an “allow” policy) is access to connected cameras. If the viewer detects this error case, it replaces the scanner element with a button to pop-up a capture window. This stand-alone window (captureQR.html) can access the camera (still subject to user approval, of course) and passes detected QR codes back to the iframe before closing itself. It’s maybe a little hokey, but gets the job done pretty well.
Picking the right camera can also be a challenge. The viewer is meant to be usable both on mobile and laptop/desktop systems, which can have very different camera setups. The browser allows cameras to be selected by “facing mode” (primarily “user” or “environment”) or by an internal ID that isn’t necessarily correlated with a user-recognizable label. The viewer tries to balance all of these with the following approach mostly in switchCamera.js.
- A default option is set in config — “environment”, which seems to be the most-often correct choice.
- Clicking on the “Switch Camera” button swaps between “user” and “environment” — the front- and rear-facing cameras in most mobile setups.
- Double-clicking on the “Switch Camera” button rotates through all of the available cameras by ID. This allows selection of, for example, a second externally-connected camera as might be in use at a provider check-in desk.
- Whenever a camera is selected, it’s remembered in browser local storage so it stays persistent for next time.
- If there’s only one camera in the system, don’t show any of this at all!
Another twist for this logic is that it needs to be usable in both the React component (Photo.js) and the pop-up simple HTML version (captureQR.html) we discussed earlier. This turns out to be more challenging than I expected, but is accomplished by including switchCamera.js as a script tag way up at the top of the React hierarchy in index.html. The most interesting thing about this code — other than some reusable bits for iterating cameras and such — is the double-click detection, which somehow is still a complicated thing to do in 2023.
Last is the code that pauses the camera after a configurable timeout. In one of our early demos, there seemed to be a steady memory leak that persisted as long as the camera was active. Typically the camera is only visible for a short time and this doesn’t matter, but if for some reason the page is left open, it can eventually crash the browser. The leak doesn’t seem to happen on all browsers or platforms, so more research to do. But to be safe, we just shut the camera off if it doesn’t find a QR code within this timeout.
Scanning Stuff: Searching the EHR
This is really an exploratory feature, but I’m betting something like it will be useful in some workflows. Primarily for SMART Health Insurance Cards, it works when physical cards are scanned into the EHR during check-in. If payers start printing SHX QR Codes on their cards, it could be useful to pull the structured FHIR data out of those QRs based on the scanned images.
When executed in EHR context, the code in Search.js digs around in the patient record looking for scanned files that might have QR codes on them. This happens in two passes:
- The code in listDocs.js queries the record for
DocumentReferenceresources that (a) might possibly be coded as payment-related and (b) have an acceptable content type (pdf, jpeg, or png). Newer documents are preferred to older ones. This is actually a pretty nice little bit of code … the biggest bummer is that in many EHR implementations, scanned documents are actually saved in a third-party system and not as FHIR resources anyways. Argh. - getDocSHX.js then digs into each of the potentially-useful resources, reading the binary contents and feeding them into qr-scanner to detect QR codes. Images files are easy, but PDFs need to be rendered into a canvas and “image-ified” before that search can happen.
Separate from the FHIR-specific stuff, there’s a nice React pattern in here too. Searching and scanning can take some time, so it happens async as part of an Effect. Nothing special about that; the neat part is that we run through the effect multiple times — once for the search and then one for each document searched. On each pass the UX is updated with information about the step — if a QR is found we route directly to the Data tab, and if not we report back and allow the user to search again if appropriate. In a world where it often seems like I’m wedging what I want to do into the React lifecycle, I was pleasantly surprised with how well this matched up.
“Scanning” Stuff: Viewer Prefix
OK this isn’t really scanning at all, but there is one more way that SHX data can make it into the viewer. If you’ve dug into the SMART Health Links spec, you’ll have encountered the viewer URL that can be prepended to the shlink:/ data itself. Our viewer supports that model via shlink.html. No muss, no fuss!
Reading the SHX: resolveSHX
No matter how they’re wrapped and packaged, the endgame for SMART Health Cards and Links is one or more FHIR bundles holding actual health information. The code in SHX.js and resources.js is responsible for sorting all of that out and building up a set of consistent structures that are (more or less) easy to render. This starts with verifySHX, which receives the scanned code — either a shc:/ or shlink:/ string, with the SHL possibly hiding behind a viewer URL hash prefix.
This function returns its work to the caller as a “status” object. The only thing guaranteed to be in the object is a shxStatus code which provides the overall result of the operation. It’s important to keep in mind that “ok” here doesn’t necessarily mean we found usable data — it just means that we were able to resolve the SHX and we were at least able to parse bundles out of it. The status of each bundle is its own thing, as we’ll see later.
The first thing verifySHX does (after setting up some exception handling) is to call resolveSHX. This dude’s job is to normalize the SHX down to two lists: one containing signed FHIR bundles (aka “verifiable credentials”) and one for bundles that are unsigned. For SMART Health Cards, this is easy — the input is a verifiable credential, so we just add it to the list and get out of dodge. (Note we’re taking advantage of the fact that our SHC verification library accepts VC values in a number of formats, including the shc:/ strings read out of QR codes.)
SMART Health Links are a more complicated story; for those we drop down into resolveSHL, which starts with decodeSHL — just a bit of fancy base64-decoding that gets us the payload so that we can throw exceptions if the payload requires a passcode or has expired. Note both of these are just hints to support our user experience — it’s up to the SHL hoster to actually enforce them. So you’ll see similar exceptions thrown later, when we actually request the manifest…
…which happens in fetchSHLManifest. In most cases this just a simple POST with a few parameters. The one exception is for SHLs with the “U” flag, used when the SHL contains only one file and bypasses a formal manifest. When our code detects this, it fakes up a manifest so that the rest of the code can proceed normally.
The rest of resolveSHX loops over each file in the manifest, downloading and decrypting the content and populating the verifiableCredentials and rawBundles arrays as appropriate. The one interesting thing here is resources that aren’t bundles at all — which is fine, we just cons up a bundle-of-one so they’re consistent for the rest of the code.
OK, take a breath. At this point we’ve taken the input SHX and turned it into two arrays — one with verifiable credentials and one with unsigned (“raw”) bundles. The next step is to turn those into a single list of bundles (statusObj.bundles) with consistent format and metadata. Let’s go.
Reading the SHX: Bundles and Organization
First we iterate over each verifiable credential we’ve collected and use smart-health-card-decoder to verify its signature and content. The directories we trust are set by configuration; be careful if you’re going to deploy any of this to production! Note that as of this writing, some of the FHIR validation rules in the decoder are a bit over-harsh; they were built for a first-generation of SMART Health Cards and need to be updated. The newest branch of the viewer actually supports a “permissive” configuration that skips some of these, but I’m going to see about a PR for the decoder soon as well.
Next we iterate over the raw bundles and add them to the list; this is obviously much simpler because there’s not much to verify.
When all is said and done, we have a bundles array that contains the original FHIR object, any bundle-specific errors, a “certStatus” field and signature metadata (if present). The last step here is to call organizeResources on each bundle. Organization has two purposes:
- Create structures that make it easy to work with the bundle and resolve references.
- Identity the bundle “type” which we’ll use to pick a renderer later on.
For #1, we create a simple array containing every resource, and two maps, one keyed by resource type and one by id (actually double-keyed by fullUrl and the resource ID itself, which provides some resiliency across different implementations). There’s a lot of redundancy here of course, but it prevents renderers re-implementing loops and lookups over and over and over.
#2 is driven by findTypeInfo, a rather grotty set of functions that dig around in the bundles to figure out “what” they are. For example, tryTypeInfoPatientSummary looks for a Composition resource coded with LOINC 60591-5. If you’re looking to add a new type to the viewer, this is where to start.
These routines also supply human-readable labels that can be used in a dropdown, and a list of resources that represent the “subject” of the data. This “subject” list drives the behavior of WrongPatientWarning.js when in EHR context — more on that later.
Another breath — now we have a nice, clean, typed list of bundles in our SHX — time to render them.
Rendering the SHX: Error cases and metadata
Way back in Data.js, the status object with all its goodness is stored in React state. Based on the shxStatus, we do one of four things:

- If we need a passcode (or if a provided passcode was rejected), render the passcode input form.
- If there was a global error reading the SHX, display it.
- If we don’t yet have a valid result, just get out of dodge (this happens on first render before the Effect validates the SHX).
- OTHERWISE, render stuff !!!
The viewer renders one bundle at a time. If the SHX contains multiple bundles, renderBundleChooser displays a dropdown allowing the user to navigate between them.
If the bundle is verifiable, ValidationInfo.js displays details about the signature in a banner above the data. There’s definitely some usability work to do on this; communicating signature information in a way that humans can actually comprehend is a tricky business.

Next, only when running in EHR context, WrongPatientWarning.js gets jammed into the page. I really like this component because I think it starts to illustrate the kind of truly smart integrations we can make happen. The component uses the FHIR query interface to identify the patient currently selected in the EHR, then compares it to the resources in the bundle.organized.typeInfo.subjects array. If a mismatch is found, a warning is displayed: you may be looking at information not connected to the EHR-selected patient.

Rendering the SHX: Type-Specific Renderers
With all the navigation, metadata and warning stuff out of the way, we can finally display bundle data itself.
renderBundle uses organized.typeInfo.btype to pick the correct component for the selected bundle. For this version, that’s:
- Coverage.js for SMART Health Insurance Cards
- PatientSummary.js for International Patient Summaries
- ImmunizationHistory.js for Immunization records
- (or if none apply, just render the JSON, ugly but ah well).
I’ll call out a few interesting implementation details of these in later sections — but in general rendering FHIR data well is just a slog through the mud. As I’ve said before: Healthcare data sucks, and FHIR is no exception. Everything can be null, everything can be a list … don’t get me started again. The methods in fhirUtil.js and fhirTables.js try to create some reusable sanity around it all, but really it just is what it is. If you want to write production-caliber FHIR display code, it’s going to be ugly and filled with defensive checks. Just learn to love the pain.
HOWTO: Add a New Type Renderer
Giving this its own section just to make it as clear is possible. The code is built so that as more types of data are shared using SMART Health Cards and Links, the viewer can be easily updated to understand and display them. This has already happened once when the good folks at Docket added the Immunization record renderer — I hope there are many more to come!
- Add a new BTYPE constant and tryTypeInfoXXX function in resources.js. The tryTypeInfoXXX function should return undefined if the bundle is not a match, otherwise an object with its BTYPE constant, a human-readable label for the bundle, and a list of the resources that identify the subject of the bundle (if any).
- Add your new rendering component to the switch statement in Data.js. Your component will receive the organized resource info and a deferred code renderer (“dcr” … see the terminologies section later for details) as input. Feel free to use or ignore fhirUtil and fhirTables — whatever works for your data type!
And that’s it. Eventually we might abstract things out even a bit more, but it’s a good start. If you have any trouble, ping me and I’ll be happy to help.
Terminologies: Deferred Code Rendering
FHIR relies heavily on codes to describe things. These codes may be relatively simple (like Marital Status, which currently includes just eleven values), or they may be mind-numbingly complex (like LOINC, commonly used for lab results and observations, which includes more than 50,000 multi-part codes).
Codes are a key tool in the attempt to make data interoperable — useful not just to the person who created it, but to anyone who receives it. A medical record that indicates “Resfriado Común” may have limited use outside of the Spanish-speaking world, but SNOMED code 82272006 means “a common cold” (or “rhume” or “verkoudheid” or whatever) no matter where it’s received. Codes also help avoid mistakes due to typos, make it easier to do robust research and use computers to work with information, and basically are just kind of great.
But when all you want to do is display a human-readable version of the code, they’re kind of annoying. There are basically an infinite number of coding systems, and as we’ve seen they can get pretty big. Some are used a lot, some very rarely. Some are published online in easily-readable formats, others are not. But everybody has to deal with them.
codes.js attempts to wrangle all of this in a way that works well within the constraints of the React client-side, synchronous rendering model. Basically it works like this:
- On first render in Data.js, a
dcrobject is created using getDeferringCodeRenderer and saved in React state. - The
dcris passed as a property to each rendering component (e.g., here). - Whenever a component needs to display human-readable text for a code, it calls dcr.safeCodeDisplay or dcr.safeCodingDisplay. If the text can be rendered synchronously, it does that. Otherwise, it queues up the codeset for asynchronous download and returns a placeholder.
- Back in useEffect, if any codesets were queued for download, a re-render is triggered which inserts the final, downloaded values.
If you’re writing a rendering component — just use the dcr methods and ignore the rest.
The list of known systems is at the top of codes.js. Each is keyed with its canonical URL, corresponding to the “system” value in FHIR Coding and CodeablConcept structures. url points to the machine-readable code set (expected to be fetched with a simple GET), and the type (default “fhir”) indicates how that source data is to be parsed into a simple code-to-text dictionary. The current list captures most codes needed for the current use cases, but will surely need to be expanded in the future.
Transformed code sets are also cached in browser-local storage (TTL and other settings are in config) — the end result being that most renderings can be completed fully-synchronously. All this is a lot of work, but the rendering developer experience is super-clean, which I’m kind of proud of.
Saving Rendered Views
The nice thing about the viewer, especially when used with a SHL viewer prefix, is that it “just works” — providers don’t need any fancy software or IT work to receive the data in a SHX. It can easily be copy/pasted (more on this in a bit!) or printed out to be incorporated into a chart. This is really good stuff and not to be underestimated.
However — the long-term endgame for interoperability is to save the data in structured form back into an EHR or other system. Unfortunately while FHIR “read” has become more-or-less expected functionality, “write” is still a little sketchy. And even when that capability is well-implemented, it’s not altogether obvious “where” to save the data. For example, we probably don’t want to fully inter-mingle patient-reported data with a condition list curated by a long-time primary care provider.
There’s a lot to figure out here, but we’ve tried to push things just one small step forward by enabling rendered views to be saved as images, either as a downloaded file or directly in the EHR. We create the image using html2canvas, a really impressive package that does exactly what we need, wrapped up inside of the divToImage function in saveDiv.js. It would probably feel more natural to do this as a PDF rather than a JPEG, but I had a really tough time getting reliable PDF rendering on the client — and since JPEG is well-supported for scanned documents, I just stuck with that.
Saving to file is a simple matter of dynamically creating and fake-clicking a link to the resulting “data” url. Saving to the EHR (when in context of course) uses our authorized FHIR connection to create a DocumentReference resource with the image directly embedded using Base64. Note that for this to work, we needed to ask for write permissions way way back in launch.html — in retrospect this should probably all be moved into config too.
Copy / Paste
If you scan a SMART Health Insurance Card SHL (e.g., the demo one here) you’ll see a number of “copy” icons placed next to important values. Of course anybody can copy/paste anything, but the idea here is to make it easy to grab the bits and pieces that are useful … for example, if you’re a provider and need to enter insurance member and group numbers into an intake form.
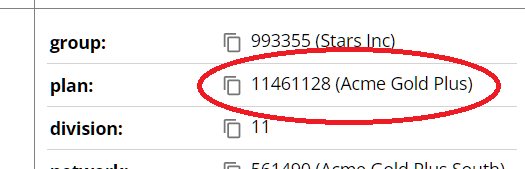
This is implemented in Copyable.js, a standalone React component that accepts two props — the copyable text and, optionally, JSX that represents a more complex rendered view of the data. You can see this at work here (also in the picture), where only the plan number should be copied, but we want to display the name as well.
The only fancy part of this component is its fallback behavior if programmatic “copy” is disallowed by browser policy, as it might be in an embedded EHR iframe. If our check for the capability fails, similar to the camera solution we pop up a small window that has the necessary rights, does the job and closes itself automatically.
DOMPurify & IFrameSandbox
The hits keep coming, this time in the PatientSummarySection.js component. IPS bundles use a Composition resource to describe how the other resources (medications, observations, etc.) in the IPS should be grouped and displayed. The document is organized into sections — the content of each section is either a (structured) set of resources, an (unstructured) Narrative block of XHTML, or both. (Actually a section can also include a set of sub-sections, but let’s ignore that for today.)
The interplay of structured resources and unstructured narrative here is pretty tricky. IPS generators have great freedom as to how they’re used — for example:
- This IPS has a “Plan of Treatment” section with only narrative xhtml.
- This one has exclusively structured data in all sections.
- This one has both narrative and structured data for all sections.
It even gets a bit weirder, because when both narrative and structured data are present they are “generally” considered to be equivalents. But the Narrative element includes a status, for which acceptable values include “additional” (i.e., the narrative has MORE information than the structured data) or “extensions” (i.e., the narrative includes content from extension elements that a structured rendering might not know how to represent). I swear every one of the meetings must end with a round of “but can we make it just a bit more complicated?”
Anyways, the viewer needs to deal with two problems here: (1) Which data do we display if both are present, and for extra fun (2) How can we safely display XHTML that we receive from an external, possibly malicious source? Awesome!
For the first problem, we make some choices while still ensuring all the data is available. Our rules are: if we have only narrative OR only structured data, show what we have. Otherwise, allow the user to toggle between views with a button. In the toggle case, default to the narrative if its status is “additional” or “extensions”, otherwise default to the structured data. This actually works out pretty well.
The second problem is a little hairier, because injecting untrusted XHTML into the browser is just a really, really sketch thing to do. I honestly can’t quite believe that the standard allows this. But it is what it is, and there’s no real option to just ignore what could be critically important clinical information. So OK.
Our primary approach is to use DOMPurify to strip out dangerous script or other content. I cannot say enough good things about the selfless contributors working on DOMPurify — it’s incredibly useful, incredibly robust, and probably the most thankless job in the open source world. Think hard about clicking their sponsor button on Github, they deserve it!
Unfortunately there are still browsers out there that aren’t supported by DOMPurify. My guess is that the intersection of these browsers with those that can use the viewer is basically zero, but you never know. So we have a fallback solution that inserts an IFrameSandbox.js component. The content is loaded into an embedded iframe with the minimal “sandbox” attribute we can use while still reasonably integrating the content into our layout. This solution isn’t great — but it’s better than nothing!
And that’s a Wrap! (for now)
There’s plenty of work left to do on the viewer, and even as I write this the “develop” branch of the code has started to move beyond what I’ve described here. But it should be (maybe more than) enough to understand what’s going on, and hopefully to save other implementers time and angst figuring out how they want their SHX receivers to work. I’m always happy to chat about this kind of thing too, so please just hit me up using the contact form or on LinkedIn or whatever.
Next job, rendering Provenance resources. So much nerd …