Lara and I shuttle regularly between Bellevue and Whidbey Island in Washington, so the Mukilteo-Clinton ferry is a big part of our life. WA actually runs the largest ferry system in the USA, with 28 boats tooting around the Puget Sound area. Super fun day trips all over the place, and the ships are pretty cool — there’s even a contracting process open right now to start converting the fleet to hybrid electric. Woot! But it can get pretty crowded — at peak summer times you can easily wait three hours to get on a boat. Recent staffing challenges have been a double-whammy and can make planning a bit tough. On the upside, a friend-of-a-friend apparently does a brisk business selling WTF (“Where’s the Ferry?”) merchandise.
Anyways, picking the right time to make the crossing is a bit of an art and requires some flexibility. We often will just plan to go “sometime after lunch,” pack up the car, and keep one eye on the live camera feeds watching for a break in the line. It occurred to me that having these cameras up on our TV would be more convenient than having to keep pulling my phone out of my pocket. Thus was born the “Washington Ferry Cameras” Roku channel, which I’ve published in the channel store and is free for anyone to use. Just search the store for “ferry” and it’ll pop up.

The rest of this article is just nerdstuff — the code is up on github and I’ll walk through the process of building and publishing for Roku. Enjoy!
The Roku Developer SDK
There are two ways to build a Roku channel: Direct Publisher and the Developer SDK. Direct Publisher is a no-code platform intended for channels that show live or on-demand videos from a structured catalog. You basically just provide a JSON feed describing the video content and all of the user experience is provided by Roku. It’s a pretty sweet system actually, making it easy for publishers and ensuring that users have a consistent streaming experience across channels.
The Developer SDK is meant for channels that do something other than just streaming video. There are tons of these “custom channels” out there — games and tools and whatnot. My ferry app clearly falls into this category, because there isn’t any video to be found and the UX is optimized for quickly scanning camera images. So that’s what I’ll be talking about here.
Roku SDK apps can be built with any text editor, and you can test/prototype BrightScript on most computers using command-line tools created by Hulu. But to actually run and package/publish apps for real you’ll need a Roku device of some sort. This page has all the details on enabling “developer mode” on the Roku. In short:
- Use the magic remote key combo (home + home + home + up + up + right + left + right + left + right) and follow the instructions that pop up.
- Save the IP address shown for your device. You’ll use it in a few ways:
- Packaging and managing apps using the web-based tools at http://YOUR_ROKU_ADDRESS
- Connecting to YOUR_ROKU_ADDRESS port 8085 with telnet or Putty to view logging output and debug live; details are here.
- Configuring your development machine to automatically deploy apps
- Enroll in the Roku development program. You can use the same email and password that you use as a Roku consumer.
Channel Structure
SDK channels are built using SceneGraph, an XML dialect for describing user interface screens, and BrightScript, a BASIC-like language for scripting behaviors and logic. It’s pretty classic stuff — SceneGraph elements each represent a user interface widget (or a background processing unit as we’ll see in a bit), arranged in a visual hierarchy that allows encapsulation of reusable “components” and event handling. We’ll get into the details, but if you’ve ever developed apps in Visual Basic it’s all going to seem pretty familiar.

Everything is interpreted on the Roku, so “building” an app just means packaging all the files into a ZIP with the right internal structure:
- A manifest file containing project-level administrivia as described in documentation.
- A source folder containing Brightscript files, most importantly Main.brs which contains the channel entrypoint.
- A components folder containing SceneGraph XML files. Honestly most of the Brightscript ends up being in here too.
There is also an images folder that contains assets including the splashscreen shown at startup and images that appear in the channel list; you’ll see these referenced in the manifest file with the format pkg:/images/IMAGENAME. “pkg” here is a file system prefix that refers to your zip file; more details are in the documentation. You’ll also see that there are duplicate images here, one for each Roku resolution (SD, HD, and FHD or “Full HD”). The Roku will auto-scale images and screens that you design to fit whatever resolution is running, but this can result in less-than pleasing results so providing custom versions for these key assets makes a lot of sense.
You can also provide alternative SceneGraph XML for different resolutions. If you think SD screens may be a big part of your user base that might be worthwhile, because the pixel “shape” is different on an SD screen vs HD and FHD. For me, it seemed totally reasonable to just work with a single FHD XML file (1920 x 1080) resolution and let the Roku manage scaling automagically.
Building and Deploying
Manually deploying an app is pretty straightforward. You can give it a try using Roku’s “Hello World” application. Download the pre-built ZIP from github, save it locally, open a browser to http://YOUR_ROKU_ADDRESS, use the “Upload” button to push the code to the Roku, and finally click “Install with zip” to make the magic happen. You should see a “Roku Developers” splash screen show up on the tv, followed by a static screen saying “Hello World.” Woot!
You can follow the same process for your own apps; just create a ZIP from the channel folder and upload it using a browser. But it’s much (much) more convenient to automate it with a makefile. This can actually be really simple (here’s the one I use for the ferry channel) if you include the app.mk helper that Roku distributes with its sample code and ensure you have versions of make, curl and zip available on your development machine. You’ll need two environment variables:
ROKU_DEV_TARGETshould be set to the IP address of your Roku.DEVPASSWORDshould be set to the password you selected when enabling developer mode on the device. Note this is not the same as the password you created when enrolling in the developer program online — this is the one you set on the device itself.
With all of this in place, you can simply run “make” and “make install” to push things up. For the ferry channel, assuming you have git installed (and your Roku is on), try:
git clone https://github.com/seanno/shutdownhook.git
cd shutdownhook/roku/channels/ferries
make
make install
Woot again! Pretty cool stuff.
Anatomy of the Ferries App
As a SceneGraph application, most of the action in the channel is in the components directory. Execution starts in “sub Main” in source/Main.brs, but all it really does is bootstrap some root objects and display the main “Scene” component defined in components/ferries.xml. You can use this Main pretty much as-is in any SceneGraph app by replacing the name of the scene.
Take a quick look at the scaffolding I’ve added for handling “deep links” (here and here). This is the mechanism that Roku uses to launch a channel directly targeting a specific video, usually from the global Roku search interface (you can read more about deep linking in my latest post about Share To Roku). It’s not directly applicable for the ferries app, but might be useful in a future channel.
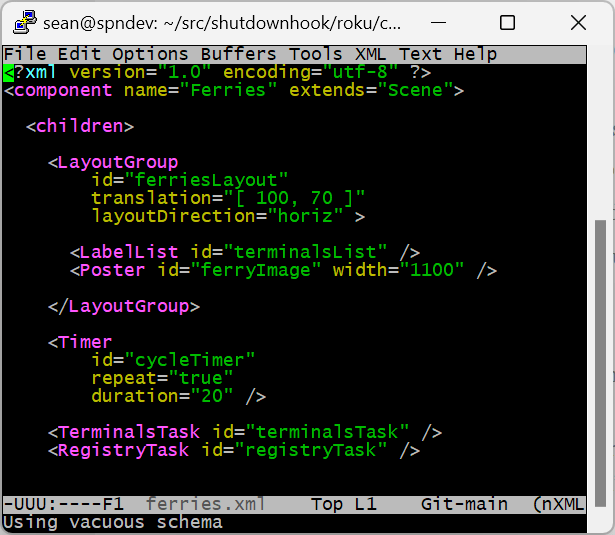
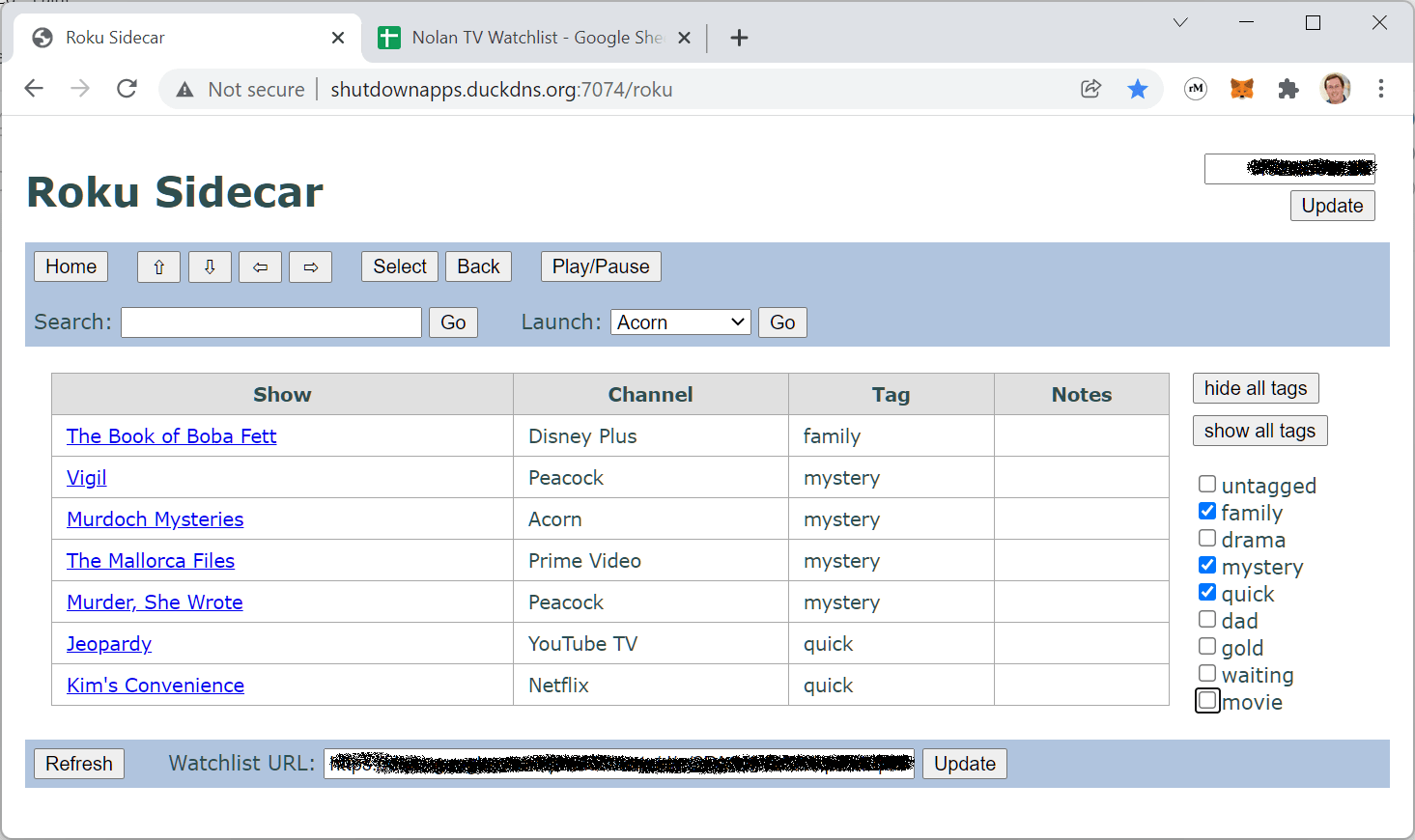
The scene layout and components are all at the top of ferries.xml. Roku supports a ton of UX components, but for my purposes the important ones are LabelList for showing/selecting terminal names and Poster for showing camera images. Because my manifest defines the app as fhd, I have a 1920 x 1080 canvas on which to place elements, with (0,0) at the top-left of the screen. The LayoutGroup component positions the list on the left and the image on the right. Fun fact: Roku recommends leaving a 5% margin around the edges to account for overscan, which apparently still exists even with non-CRT televisions, which is the purpose of the “translation” attribute that offsets the group to (100,70).
Below the visible UX elements are three invisible components (Tasks) that help manage program flow and threading:
- A
Timercomponent is used to cycle through camera images every twenty seconds. - A custom
TerminalsTaskthat loads the terminal names and camera URLs from the WSDOT site. - A custom
RegistryTaskthat saves the currently-selected terminal so the channel remembers your last selection.
Each XML file in the components directory (visible or not) actually defines an SceneGraph object with methods defined in the BrightScript CDATA section below the XML itself. When a scene is instantiated, it and all the children defined in its xml are created and their “init” functions are called. The SceneGraph thread then dispatches events to components in the scene until it’s destroyed, either because the user closed the channel with the back or home buttons, or because the channel itself navigates to a new scene.
Channel Threading
It’s actually pretty important to understand how threads work within a channel:
- The main BrightScript thread runs the message loop defined in
Main.brs. When this loop exits, the channel is closed. - The SceneGraph render thread is where UX events happen. It’s super-important that this thread doesn’t block, for example by waiting on a network request.
- Task threads are created by
Taskcomponents (in our case theTimer,TerminalsTaskandRegistryTask) to perform background work.
The most typical (but not only) pattern for using background tasks looks like this:
- The Task defines public fields in its
<interface>tag. These fields may be used for input and/or output values. - The task caller (often a handler in the render thread) starts the task thread by:
- Setting input fields on the task, if any.
- Calling “
observeField” on the output task fields (if any), specifying a method to be called when the value is updated. - Setting the “
control” field on the task to “RUN.”
- The task does its work and (if applicable) sets the value of its output fields.
- This triggers the original caller’s “
observeField” method to be executed on the caller’s thread, where it can act on the results of the task.
Data Scoping and “m”
Throughout the component code you’ll see references to the magic SceneGraph “m” object. The details are described in the SDK documentation, but it’s really just an associative array that is set up for use by components like this:
m.WHATEVERreferences data in component scope — basically object fields in typical OO parlance.m.globalreferences data in global scope.m.topis a magic pre-set that references the top of the component hierarchy for whatever component it’s called from (pretty much “this“). I really only usem.topwhen looking up components by id, kind of the same way I’d usedocument.getElementByIdin classic Javascript.
If you dig too much into the documentation on this it can get a bit confusing, because “m” as described above is provided by SceneGraph, which sits on top of BrightScript, which actually has its own concept of “m” which is basically just #1. This is one of those cases where it seems better to just wave our hands and not ask a lot of questions.
OK, enough of that — let’s dig into each of the components in more detail.
ferries.xml
This component is the UX workhorse; we already saw the XML that defines the elements in the scene at the top of the file. The Brightscript section is mostly concerned with handling UX and background events.
On init the component wires up handlers to be called when the focus (using the up/down arrow buttons) or selection (using the OK button) changes in the terminal list. It then starts the terminalsTask and hooks up the onContentReady handler to be called when that task completes.
When that happens, onContentReady populates the LabelList with the list of terminal names and queries the registryTask (synchronously) to determine if the user has selected a terminal in a previous run of the channel. If so, focus is set to that terminal, otherwise it just defaults to the first one in the list (it pays to be “Anacortes”). cycleImage is called to kickstart image display, and the cycleTimer is started to rotate images (the “Timer” we use is just a specialized Task node — it takes care of the thread stuff and just runs our callback on the UX thread at the specified interval).
The next few methods deal with the events that change the terminal or image. onKeyEvent receives (duh) events sent by the remote control, cycling the images left or right. onItemFocused sets the current terminal name, resets the image index to start with the first camera, and kicks of a registryTask thread to remember the new terminal for the future. onItemSelected and onTimer just flip to the next camera image.
The timer behavior is a bit wonky — the image is cycled every 20 seconds regardless of when the last UX event happened. So you might choose a new terminal and have the first image shown for just a second before the timer rotates away from it. In practice this doesn’t seem to impact the experience much, so I just didn’t worry about it.
The last bit of code in this component is cycleImage, which does the hard work of figuring out and showing the right “next” image. The array handling is kind of nitpicky because each terminal can have a different number of associated cameras; there’s probably a cleaner way of dealing with it but I opted for being very explicit. The code also scales the image to fit correctly into our 1100 pixel width without getting distorted, and then sets the URL with a random query string parameter that ensures the Roku doesn’t just return a previously-cached image. Tada!
terminalsTask.xml
This component has one job — load up the terminal and camera data from the WSDOT site and hand it back to the ferries component. Instead of a <children> XML node at the top, we have an <interface> node that defines how the task interacts with the outside world. In this case it’s just one field (“ferries”) which receives the processed data.
The value m.top.functionName tells the task what function to run when it’s control is set to RUN. We set the value in our init function so callers don’t need to care. Interestingly though, you can have a task with multiple entrypoints and let the caller choose by setting this value before setting the control. None of that fancy-pants “encapsulation” in Brightscript!
The Roku SDK provides some nice helpers for fetching data from URLs (remember to set the cert bundle!) and parsing JSON, so most of this component is pretty simple. The only bummer is that the WSDOT JSON is just a little bit wonky, so we have to “fix it up” before we can use it in our channel.
It seems so long ago now, but the original JSON was really just JavaScript literal expressions. You can say something like this in JavaScript to define an object with custom fields: var foo = { strField: “hi”, intField: 20 }. People decided this was cool and set up their API methods to just return the part in curly braces, replacing the client-side JavaScript with something like: var foo = eval(stringWeFetched). “eval” is the uber-useful and uber-dangerous JavaScript method that just compiles and executes code, so this worked great.
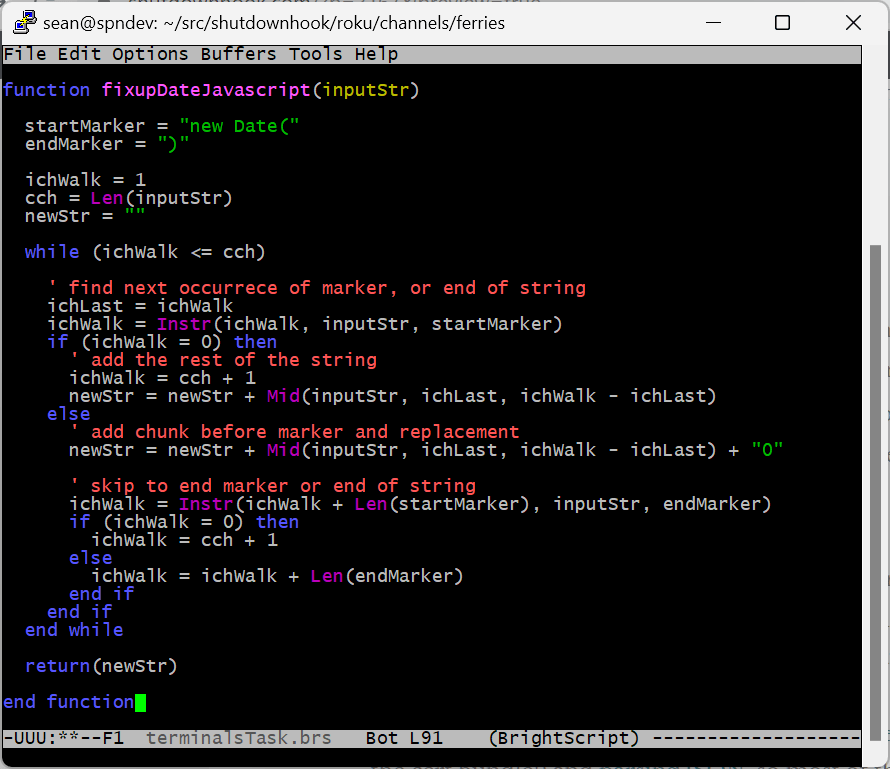
A side effect of this approach was that you could actually use any legal JavaScript in your “JSON” — for example, { intField: 1 + 3 } (i.e., “4”). But of course we all started using JSON everywhere, and in all of those non-JavaScript environments “eval” doesn’t exist. And even in JavaScript it ends up being a huge security vulnerability. So these little hacks were disallowed, first class parsers (like my beloved gson) were created, and the JSON we know and love today came into its own.
You may have deduced from this digression that the WSDOT JSON actually contains live JavaScript — and you’re right. Just a few Date constructors, but it’s enough to confuse the Roku JSON parser. The code in fixupDateJavascript is just good old grotty string manipulation that hacks it back to something parsable. This was actually a really nice time to have Hulu’s command-line brs tool available because I didn’t have to keep pushing code up to the Roku to get it right.
registryTask.xml
Most people have a “home” ferry terminal. In fact, we have two — Mukilteo when we’re in Bellevue and Clinton on the island. It’d be super-annoying to have to use the remote to select that terminal every time the channel starts, so we save the “last viewed” terminal in the Roku registry as a preference.
The registry is meant for per-device preference data, so it’s pretty limited in size at 16kb (still way more than we need). The only trick is that flushing the registry to storage can block the UX thread — probably not enough to matter, but to be a good citizen I put the logic into a background task. Each time a new terminal is selected, the UX thread makes a fire-and-forget call that writes and flushes the value. Looking at this code now I probably should have just created one roRegistrySection object on init and stored it in m … ah well.
The flip side of storing the terminal value is getting it back when the channel starts up. I wanted to keep all the registry logic in one place, so I did this by adding a public synchronous method to the registryTask interface. Calling this method is a bit ugly but hey, you can’t have everything. Once you start to get used to how the language works you can actually keep things pretty tidy.
Packaging and Publishing
Once the channel is working in “dev” mode, the next step is to get it published to the channel store for others to use. For wider testing purposes, it can be launched immediately as a “beta” channel that users install using a web link. There used to be a brisk business in “private” (cough cough, porn) Roku channels using this mechanism, but Roku shut that down last year by limiting beta channels to twenty users and auto-expiring them after 120 days. Still a great vehicle for testing, but not so much for channel publishing. For that you now have to go official, which involves pretty standard “app” type stuff like setting up privacy policies and passing certification tests.
Either way, the first step is to “package” your channel. Annoyingly this has to happen on your Roku device:
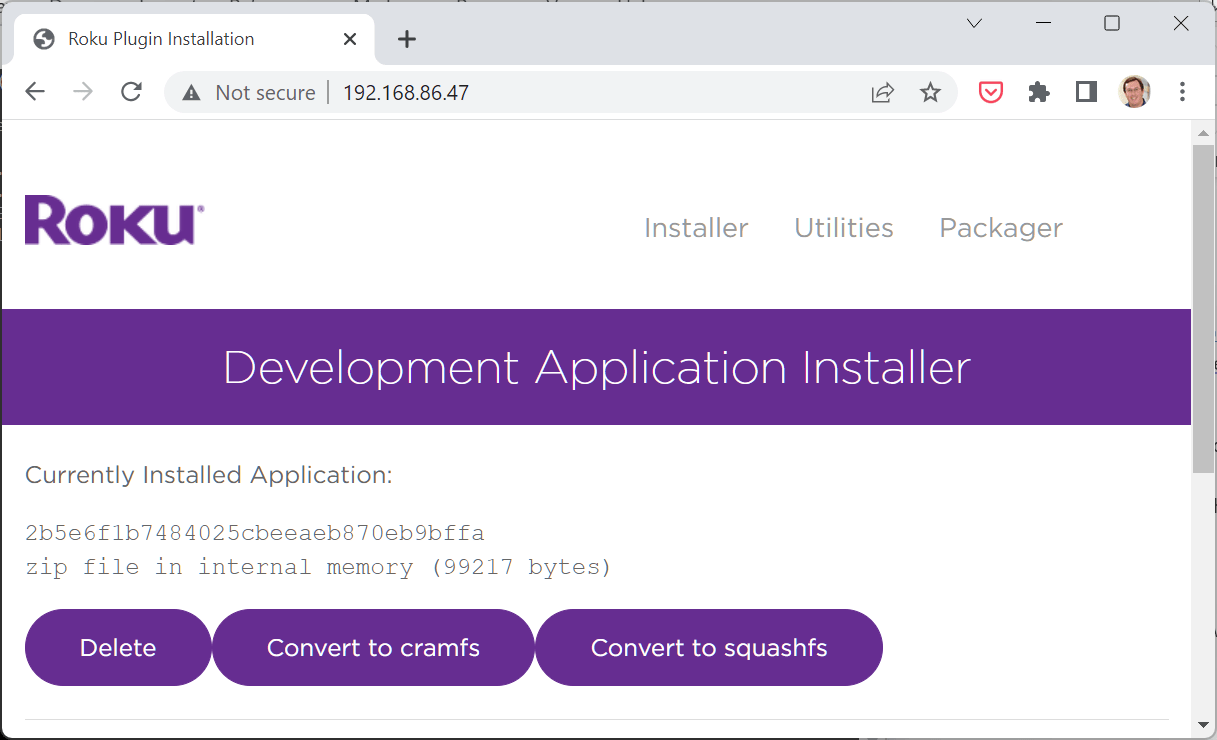
- Set up your Roku with a signing key. Instructions are here; remember to save the generated password! (Aside: I love it when instructions say “if it doesn’t work, try the same thing again.”)
- Make sure the “ready-for-prime-time” version of your channel is uploaded to your Roku device.
- Use a web browser to visit http://YOUR_ROKU_ADDRESS; you’ll land on the “Development Application Installer” page showing some data on the sideloaded app.
- Click the “Convert to Cramfs” button. You actually don’t need to compress your app, but why wouldn’t you? Apparently “Squashfs” is a bit more efficient but it creates a Roku version dependency; not worth dealing with that unless your channel already relies on newer versions.
- Click the “Packager” link, provide an app name and the password from genkey, and click “Package.”
- Woo hoo! You’ll now have a link from which you can download your channel package file. Do that.
Almost there! The last step is to add your channel using the Roku developer dashboard. This ends up being a big checklist of administrative stuff — for Beta channels you can ignore most of it, but I’ll make some notes on each section because eventually you’ll need to slog through them all:
- Properties are pretty self-explanatory. You’ll need to host a privacy and terms of use page somewhere and make some declarations about whether the channel is targeted at kids, etc.. For me the most important part of this ended up being the “Classification” dropdown. A lot of the “channel behavior” requirements later on just didn’t apply to my channel — not surprisingly Roku is pretty focused on channels that show videos. By choosing “App/Utility” as my classification I was able to skip over some of those (thanks support forum).
- Channel Store Info is all about marketing stuff that shows up in the (of course) channel store.
- Monetization didn’t apply for me so an easy skip.
- Screenshots are weird. They’re optional, so I just bailed for now. The Roku “Utilities” page at http://YOUR_ROKU_ADDRESS claims to be able to take screenshots from the device itself, but either the tool fails or it leaves out the ferry image. I need to just cons one up but it’s a hassle — will get there!
- Support Information is obvious. Be careful about what email address you use!
- Package Upload is where you provide the package file we created earlier.
- Static Analysis runs some offline code quality tools — you need to pass without errors to publish.
- Channel Behavior Analysis only appears if it’s applicable for your channel (i.e., if it shows video). The primary metrics are time for the channel to show the home page, and time for video to start rendering. You’ll need to handle deep linking (remember when we saw that in
Main.brs) and fire a few “beacons” that help the Roku measure performance. - Preview and Publish just shows a summary of channel information and a checklist that shows your progress on all of the bullets above. When you’re ready, you can schedule a time for the channel to go live and you’re off to the races. Whew.
That’s it! The last bit was a bit of a whirlwind — I wanted to call out the key gotchas to help keep you from getting stuck, but it’s by far the least interesting part of building a channel. Once I got my head around the basic BrightScript/SceneGraph concepts I really quite enjoyed the development process. I’ve been thinking about a few other channels that might be fun — my son suggested a flight tracker, and I’ve always been interested in ecommerce on the TV. Not sure when any of that will happen, though … so many cool things to try!
Please let me know if you have any issues with the code or with the channel, always happy to help! Until next time.


_-_Google_Art_Project.jpg)