
The beach outside our Whidbey place is amazing. There’s about twenty yards of firm sand and rocks along the shore, then a broad, flat, soft expanse of sand/mud/clay for just under 100 yards, then maybe 30 yards of firm sandbars. Beyond the sandbars, the channel drops to a depth of about 500 feet or so (the first “steps” along this drop-off are the best places to drop a crab pot).
The tide sweeping in and out over this shallow area changes our back yard dramatically from hour to hour. At the highest high tide there’s no beach at all — in the Spring whales swim just a few yards away, sucking ghost shrimp out of the mud flats. During summer low-low tides, we head out to the sand bars where you can dig for horse clams and pick up crabs hiding in the eel grass (while Copper chases seagulls for miles).

I know it sounds a bit out there, but the rhythm of our days really does sync up with the water — and it’s a wonderful way to live. “What’s the tide doing today?” is the first question everybody seems to ask as they come down for coffee in the morning. And that, my friends, sounds like fodder for another fun project.
What’s the tide doing today?
NOAA publishes tide information that drives a ton of apps — I use Tides Near Me on my phone and the TideGuide skill on Alexa, and both are great. But what I really want is something that shows me exactly what the tide will look like in my back yard. For some reason I have a really hard time correlating tide numbers to actual conditions, so an image really helps. (As an aside, difficulty associating numbers with reality is a regular thing for me. I find it very curious.) For example, if you were to stand on the deck in the afternoon on September 30, what exactly would you see? Maybe this?

Those images are generated by (a) predicting what the tide and weather will be like at a point in time, and then (b) selecting a past image that best fits these parameters from a historical database generated using an exterior webcam, NOAA data and my Tempest weather station. So the pictures are real, but time-shifted into the future. Spooooky!
Actually, my ultimate goal is to create a driftwood display piece that includes a rotating version of these images together with a nice antique-style analog tide clock. But for today, let’s just focus on predictions and images.
How Tides Work
Ocean Tides are a rabbit hole you can go down a looong way — fascinating stuff. This National Geographic article is a nice intro, and this primer by UW professor Parker MacCready really gets into the weeds. To my understanding, there are at six primary factors that contribute to tide action:
- Variations in pull from the Moon’s gravity on the Earth. The side facing the Moon has increased gravity, and the side opposite the moon has slightly less. Both of these cause liquid water on the surface to “bulge” along this axis (more on the closer side, less on the far side).
- The same thing happens due to the Sun’s gravity, but less so. Tides are most extreme when the sun and moon “line up” and work together; least so when they are at right angles to each other.
- The Earth is spinning, which combines with orbital movement to change which parts of the Earth are being pulled/pushed the most at any given time.
- The Earth is tilted, which changes the angles and magnitude of the forces as the seasons change. One consequence of this is that we tend to have daytime lows in the Summer and nighttime lows in the Winter.
- Weather (short-term and seasonal) can change the amount of water in a specific location (storm surges being a dramatic example).
- Local geography changes the practical impact of tides in specific locations (e.g., levels present differently over a wide flat area like my beach vs. in a narrow fjord).
All of this makes it really tough to accurately predict tide levels at a particular time in a particular place. Behavior at a given location can be described reasonably well by combining thirty-seven distinct sine waves, each defined by a unique “harmonic constituent.” NOAA reverse-engineers these constituents by dropping buoys in the ocean, measuring actual tide levels over a period of months and years, and doing the math. Our closest “harmonic” or “primary” station is across the water in Everett.
“Subordinate” stations (our closest is Sandy Point) have fewer historical measurements — just enough to compute differences from a primary station (Seattle in this case). But here’s the really interesting bit — most of these “stations” don’t actually have physical sensors at all! The Sandy Point buoy was only in place from February to April, 1977. In Everett, it was there for about five months in late 1995. To find an actual buoy you have to zoom all the way out to Port Townsend! This seems a bit like cheating, but I guess it works? Wild.
You can query NOAA for tide predications at any of these stations, but unless there’s a physical buoy all you really get is high and low tide estimates. If you want to predict water level for a time between the extremes, you need to interpolate. Let’s take a look at that.
The Rule of Twelfths

It turns out that sailors have been doing this kind of estimation for a long, long time using the “Rule of Twelfths.” The RoT says that if you divide the span between extremes into six parts, 1/12 of the change happens in the first part; 2/12 in the next; then 3/12, 3/12 again, 2/12 and 1/12 to finish it out. Since the period between tides is about six hours, it’s a pretty easy mental calculation that would have been good to know when I was fifteen years old trying to gun my dad’s boat through the channel off of Ocean Point (spoiler alert: too shallow).
Anyways, I use this rule together with data from NOAA and simple interpolation to predict tide levels on my beach for any given timepoint. The code is in NOAA.java and basically works like this:
- The NOAA class exposes a single method “getPredictions” that queries NOAA for tide extremes from one day before to two days after a given timepoint.
- The extremes are added to a list, as well as five RoT timepoints between each of them.
- The resulting list is returned to the caller as a Predictions object.
The Predictions object exposes a few methods, but the most interesting one is estimateTide, which does a binary search to find the predictions before and after the requested timepoint, then uses linear interpolation to return a best-guess water level. The resulting estimations aren’t perfect, but they are really very accurate — more than good enough for our purposes. Woo hoo!
Stepping Back
OK, let’s back up a bit and look at the code more broadly. Tides is a web app that primarily exposes a single endpoint /predict. It’s running on my trusty Rackspace server, and as always the code is on github. To build and run it, you’ll need a JDK v11 or greater, git and mvn. The following will build up the dependencies and a fat jar with everything you need:
git clone https://github.com/seanno/shutdownhook.git
cd shutdownhook/toolbox && mvn clean package install
cd ../weather && mvn clean package install
cd ../tides && mvn clean package
To run the app you’ll need a config file — which may be challenging because it expects configuration information for a Tempest weather station and a webcam for capturing images. But if you have that stuff, go to town! Honestly I think the code would still work pretty well without any of the weather information — if you are interested in running that way let me know and I’d be happy to fix things up so that runs without crashing.
The code breaks down like this:
- Camera.java is a very simple wrapper that fetches live images from the webcam.
- NOAA.java fetches tide predictions, augments them with the RoT, and does interpolation as discussed previously.
- Weather.java manages interactions with the Tempest. It relies on code I wrote awhile ago and discuss here.
- TideStore.java is a simple SQL and file system store.
- Tides.java is a domain layer that pulls all the bits and pieces together.
- Server.java implements the web interface, using the WebServer class I build long ago.
Capturing Images and Metadata
None of this works without a pretty significant collection of metadata-tagged historical images. And you can’t capture images without a camera — so that was step one here. I have a ton of Ring cameras and I love them, but they are nearly impossible to access programmatically. Sure there are some reverse-engineered libraries, and they “kind of” work, but reliably capturing an image “right now” is a complicated and ultimately only semi-successful mess. So instead I just picked up a simple camera that is civilized enough to just expose the damn image with a URL.
Running the app with the parameter “capture” tells it to call Tides.captureCurrentTide rather than running the web server. This method:
- Captures the current “day of year” (basically 1 – 365) and “minute of day” (0 – 1,439). It turns out that these two values are the most critical for finding a good match (after tide height of course) — being near the same time of day at the same time of year really defines the “look” of the ocean and sky, at least here in the Pacific Northwest.
- Loads current weather metrics from the Tempest.
- Estimates the current tide level.
- Captures an image from the webcam.
- And finally, writes it all to the TideStore.
The capture stuff runs twice hourly via cron job on a little mini pc I use for random household stuff; super-handy to have a few of these lying around! Once a day, another cron job pushes new images and a copy of the database to an Azure container — a nice backup story for all those images that also lands them in a cloud location perfect for serving beyond my home network. Stage one, complete.
Picking an Image
The code to pick an image for a set of timepoints is for sure the most interesting part of this project. My rather old-school approach starts in Tides.forecastTides, which takes a series of timepoints and returns predictions for each (as well as data about nearby extremes which I’ll talk about later). The timepoints must be presented in order, and typically are clustered pretty closely — e.g., for the /predict endpoint we generate predictions for +1, +3 and +6 hours from now, plus the next three days at noon.
First we load up NOAA predictions and, if any of the timepoints are within the bounds of the Tempest forecast, that data as well. The Tempest can forecast about ten days ahead, so in normal use that works fine (the code actually interpolates weather in the same way we do for tides). As we iterate through the timepoints, we load new NOAA predictions if needed.
Armed with this stuff, the real core of the work happens in Tides.forecastTide. The first pass is in TideStore.queryClosest, which uses a series of thresholds to find images within given ranges of tide height, day of year and hour of day. We start with a very tight threshold — tide within .25 feet, day of year within 10 days and hour of day within 20 minutes. If we don’t find any, we fall back to .5/20/20, and so on from there until our last try is pretty wide at 1/120/120. If we can’t find anything at that point we just give up — hard to even squint and see that as a match. The good news is, even after collecting data for just about a month, we already succeed most of the time.
By querying in stages like this, we end up with a candidate pool of images that, from a tide/time perspective, we consider “equivalently good.” Of course we may just find a single image and have to use it, but typically we’ll find a few. In the second pass, we sort the candidates by fit to the predicted weather metrics. Again we use some thresholding here — e.g., pressure values within 2mb of each other are considered equivalent.
At the end of the day, this is futzy, heuristic stuff and it’s hard to know if all the thresholds and choices are correct. I’ve made myself feel better about it for now by building a testing endpoint that takes a full day of actual images and displays them side-by-side with the images we would have predicted without that day’s history. I’ve pasted a few results for August 30 below, but try the link for yourself, it’s fun to scroll through!

Other Ways We Could Do This: Vectors
Our approach works pretty well, even with a small (but growing!) historical database. But it’s always useful to consider other ideas. One way would be to replace my hand-tuned approach with vector-based selection. Vector distance is a compelling way to rank items by similarity across an arbitrary number of dimensions; it appeals to me because it’s pretty easy to visualize. Say you want to determine how similar other things are to a banana, using the properties “yellowness” and “mushiness” (aside: bananas are gross). You might place them on a graph like the one here.
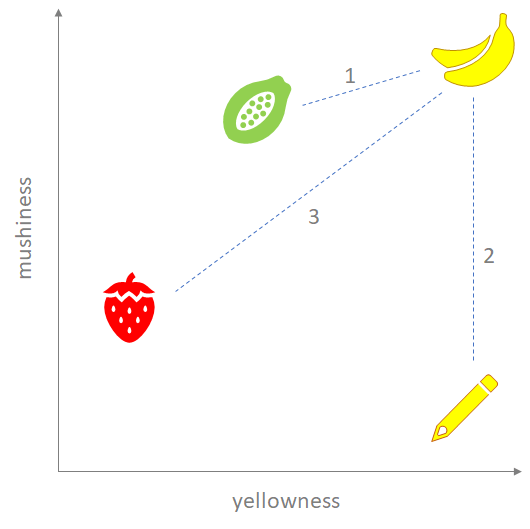
Computing the Euclidian distance between the items gives a measure of similarity, and it kind of works! Between a papaya, strawberry and pencil, the papaya is intuitively the most similar. So that’s cool, and while in this example we’re only using two dimensions, the same approach works for “N” — it’s just harder to visualize.
But things are never that simple — if you look a little more deeply, it’s hard to argue that the pencil is closer to a banana than the strawberry. So what’s going on? It turns out that a good vector metric needs to address three common pitfalls:
- Are you using the right dimensions? This is obvious — mushiness and yellowness probably aren’t the be-all-end-all attributes for banana similarity.
- Are your dimensions properly normalized? In my tide case, UV measurements range from 0 – 10, while humidity can range from 0 – 100. So a distance of “1” is a 10% shift in UV, but only a 1% shift in humidity. If these values aren’t normalized to a comparable scale, humidity will swamp UV — probably not what we want.
- How do you deal with outliers? This is our pencil-vs-strawberry issue. A pencil is “so yellow” that even though it doesn’t remotely match the other dimension, it sneaks in there.
These are all easily fixable, but require many of the same judgment calls I was making anyways. And it’s a bit challenging to do an efficient vector sort in a SQL database — a good excuse to play with vector databases, but didn’t seem like a big enough advantage to worry about for this scenario.
Other Ways We Could Do This: AI

My friend Zach suggested this option and it’s super-intriguing. Systems like DALL-E generate images from text descriptions — surprisingly effective even in their most generic form! The image here is a response to the prompt “a photographic image of the ocean at low tide east of Whidbey Island, Washington.” That’s pretty spooky — even includes an island that look a lot like Hat from our place.
With a baseline like this, it should be pretty easy to use the historical database to specialty-train a model that generates “future” tide images out of thin air. This is exciting enough that I’m putting on my list of things to try — but at the same time, there’s something just a bit distasteful about deep-faking it. More on this sometime soon!
A Few Loose Ends
The rest of the code is just delivery, mostly in Server.java, using the WebServer and Template classes that make up many of my projects.
One nice little twist — remember that I pushed the images and database to an Azure container for backup. There’s nothing in those files that needs to be secret, so I configured the container for public web access. Doing this lets me serve the images directly from Azure, rather than duplicating them on my Rackspace server.
I also forgot to mention the Extremes part of tide forecasting. It turns out that it’s not really enough to know where the water is at a point in time. You want to know whether it’s rising or falling, and when it will hit the next low or high. We just carry that along with us so we can display it properly on the web page. It’s always small things like this that make the difference between a really useful dashboard and one that falls short.
I’ll definitely tweak the UX a bit when I figure out how to put it into a fancy display piece. And maybe I’ll set it up so I can rotate predictions on my Roku in between checking the ferry cameras! But that is for another day and another post. I had a great time with this one; hope you’ve enjoyed reading about it as well. Now, off to walk the beach!









