Heads up, this is another nerdy one! ShareToRoku is available on the Google Play store. All of the client and server code is up on my github under MIT license; I hope folks find it useful and/or interesting.
Algorithms are the cool kids of software engineering. We spend whole semesters learning to sort and find stuff. Spreadsheet “recalc” engines revolutionized numeric analysis. Alignment algorithms power advances in biotechnology. Machine learning algorithms impress and terrify us with their ability to find patterns in oceans of data. They all deserve their rep!

But as great as they are, algorithms are hapless unless they receive inputs in a format they understand — their “model” of the world. And it turns out that these models are really quite strict — data that doesn’t fit exactly can really gum up the works. As engineers we often fail to appreciate just how “unnatural” this rigidity is. If I’m emptying the dishwasher, finding a spork amongst the silverware doesn’t cause my head to explode — even if there isn’t a “spork” section in the drawer (I probably just put it in with the spoons). Discovering a flip-top on my toothpaste rather than a twist cap really isn’t a problem. I can even adapt when the postman leaves packages on top of the package bin, rather than inside of it. Any one of these could easily stop a robot cold (so lame).
It’s easy to forget, because today’s models are increasingly vast and impressive, and better every day at dealing with the unexpected. Tesla’s Autopilot can easily be mistaken for magic — but as all of us who have trusted it to exit 405 North onto NE 8th know, the same weaknesses are still hiding in there under the covers. But that’s another story.
Anyhoo, the point is that our algorithms are only useful if we can feed them data that fits their models. And the code that does that is the workhorse of the world. Maybe not the sexiest stuff out there, but almost every problem we encounter in the real world boils down to data normalization. So you’d better get good at it.
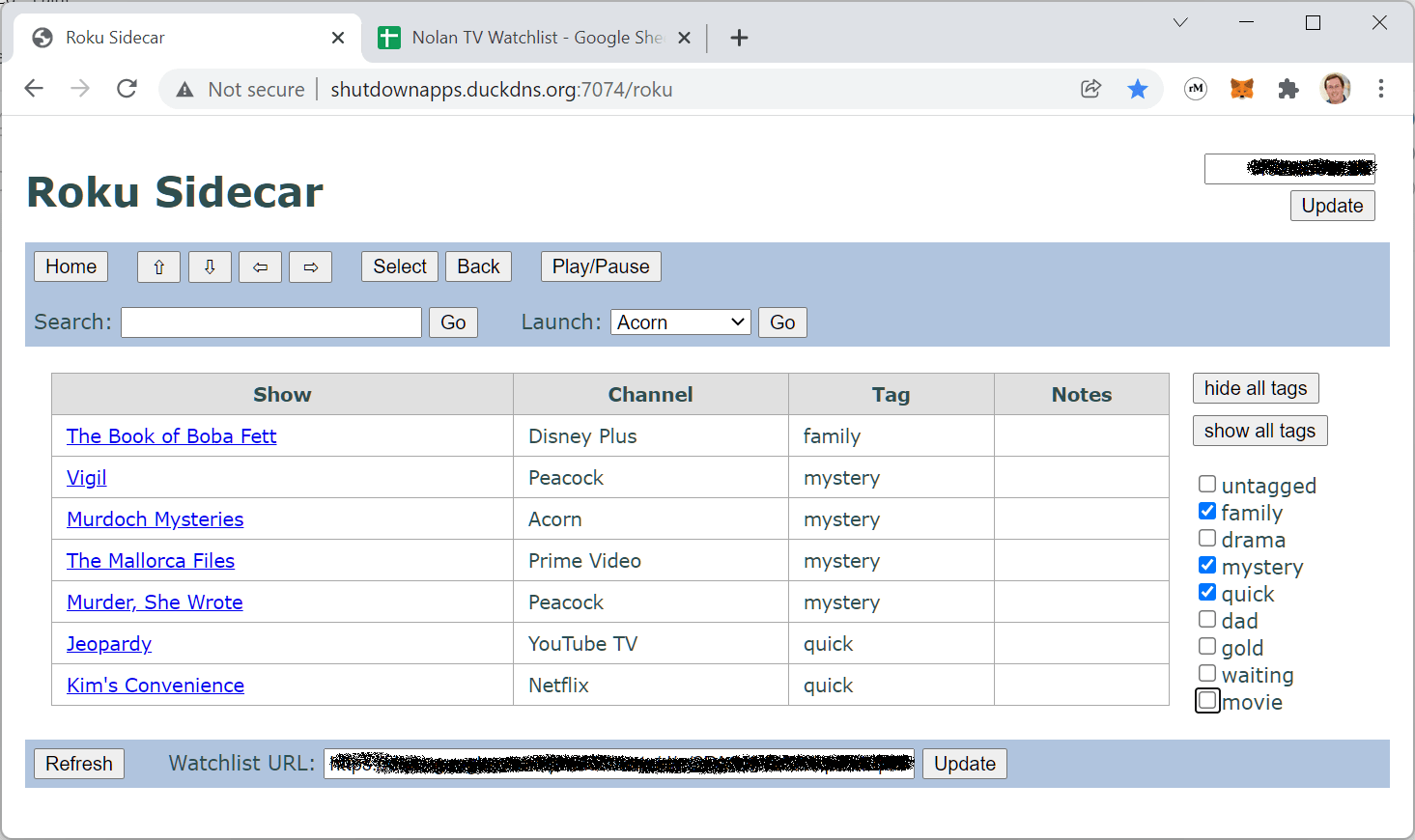
Share to Roku (Release 6)
My little Android TV-watching app is a great (in miniature) example of this dynamic at work. If you read the original post, you’ll recall that it uses the Android “share” feature to launch TV shows and movies on a Roku device. For example, you can share from the TV Time app to watch the latest episode of a show, or launch a movie directly from its review at the New York Times. Quite handy, but it turns out to be pretty hard to translate from what apps “share” to something specific enough to target the right show. Let’s take a look.
First, the “algorithm” at play here is the code that tells the Roku to play content. We use two methods of the Roku ECP API for this:
- Deep Linking is ideal because it lets us launch a specific video on a specific channel. Unfortunately the identifiers used aren’t standard across channels, and they aren’t published — it’s a private language between Roku and their channel providers. Sometimes we can figure it out, though — more on this later.
- Search is a feature-rich interface for jumping into the Roku search interface. It allows the caller to “hint” the search with channel identifiers and such, and in certain cases will auto-start the content it finds. But it’s hard to make it do the right thing. And even when it’s working great it won’t jump to specific episodes, just seasons.
Armed with this data, it’s pretty easy to slap together the optimal API request. You can see it happening in ShareToRokuActivity.resolveAndSendSearch — in short, if we can narrow down to a known channel we try to launch the show there, otherwise we let the Roku search do its best. Getting that data in the first place is where the magic really happens.
A Babel of Inputs
The Android Sharesheet is a pretty general-purpose app-to-app sharing mechanism, but in practice it’s mostly used to share web pages or social media content through text or email or whatever. So most data comes through as unstructured text, links and images. Our job is to make sense of this and turn it into the most specific show data we can. A few examples:
| App / Source | Shared Data | Ideal Target |
|---|---|---|
| 1. TV Time Episode Page | Show Me the Love on TV Time https://tvtime.com/r/2AID4 | “Trying” Season 1 Episode 6 on AppleTV+ |
| 2. Chrome nytimes.com Movie Review (No text selection) | https://www.nytimes.com/2022/11/22/movies/strange-world-review.html | “Strange World” on Disney+ |
| 3. Chrome Wikipedia page (movie title selected) | “Joe Versus the Volcano” https://en.wikipedia.org/wiki/Joe_Versus_the_Volcano#:~:text=Search-,Joe%20Versus%20the%20Volcano,-Article | “Joe Versus the Volcano” on multiple streaming services |
| 4. YouTube Video | https://youtu.be/zH14EyiSlas | “When you say nothing at all” cover by Reina del Cid on YouTube |
| 5. Amazon Prime Movie | Hey I’m watching Black Adam. Check it out now on Prime Video! https://watch.amazon.com/detail?gti=amzn1.dv.gti.1a7638b2-3f5e-464a-a271-07c2e2ec1f8c&ref_=atv_dp_share_mv&r=web | “Black Adam” on Amazon Prime |
| 6. Netflix Series Page | Seen “Love” on Netflix yet? https://www.netflix.com/us/title/80026506?s=a&trkid=13747225&t=more&vlang=en&clip=80244686 | “Love” Season 1 Episode 1 on Netflix |
| 7. Search text entered directly into ShareToRoku | Project Runway Season 5 | “Project Runway” Season 5 on multiple streaming services. |
Pipelines and Plugins
All but the simplest normalization code typically breaks down into a collection of rules, each targeted at a particular type of input. The rules are strung together into a pipeline, each doing its little bit to clean things up along the way. This approach makes it easy to add new rules into the mix (and retire obsolete ones) in a modular, evolutionary way.
After experimenting a bit (a lot), I settled on a two-phase approach to my pipeline:
- Iterate over a list of “parsers” until one reports that it understands the basic format of the input data.
- Iterate over a list of “refiners” that try to enhance the initial model by cleaning up text, identifying target channels, etc.
_-_Google_Art_Project.jpg)
Each of these is defined by a standard Java interface and strung together in SearchController.java. A fancier approach would be to instantiate and order the implementations through configuration, but that seemed like serious overkill for my little hobby app. If you’re working with a team of multiple developers, or expect to be adding and removing components regularly, that calculus probably looks a bit different.
This split between “parsers” and “refiners” wasn’t obvious at first. Whenever I face a messy normalization problem, I start by writing a ton of if/then spaghetti, usually in pseudocode. That may seem backwards, but it can be hard to create an elegant approach until I lay out all the variations on the table. Once that’s in front of me, it becomes much easier to identify commonalities and patterns that lead to an optimal pipeline.
Parsers
“Parsers” in our use case recognize input from specific sources and extract key elements, such as the text most likely to represent a series name. As of today there are three in production:
TheTVDB Parser (Lookup.java)
TV Time and a few other apps are powered by TheTVDB, a community-driven database of TV and movie metadata. The folks there were nice enough to grant me access to the API, which I use to recognize and decode TV Time sharing URLs (example 1 in the table). This is a four step process:
- Translate the short URL into their canonical URL. E.g., the short URL in example 1 resolves to https://www.tvtime.com/show/375903/episode/7693526&pid=tvtime_android.
- Extract the series (375903) and/or episode (7693526) identifiers from the URL.
- Use the API to turn these identifiers into show metadata and translate it into a parsed result.
- Apply some final ad-hoc tweaks to the result before returning it.
All of this data is cached using a small SQLite database so that we don’t make too many calls directly to the API. I’m quite proud of the toolbox implementation I put together for this in CachingProxy.java, but that’s an article for another day.
UrlParser.java
UrlParser takes advantage of the fact that many apps send a URL that includes their own internal show identifiers, and often these internal identifiers are the same ones they use for “Deep Linking” with Roku. The parser is configured with entries that include a “marker” string — a unique URL fragment that identifies a particular — together with a Roku channel identifier and some extra sugar not worth worrying about. When the marker is found and an ID extracted, this parser can return enough information to jump directly into a channel. Woo hoo!
SyntaxParser.java
This last parser is kind of a last gasp that tries to clean up share text we haven’t already figured out. For example, it extracts just the search text from a Chrome share, and identifies the common suffix “SxEy” where x is a season and y is an episode number. I expect I’ll add more in here over time but it’s a reasonable start.
Refiners
Once we have the basics of the input — we’ve extracted a clean search string and maybe taken a first cut at identifying the season and channels — a series of “refiners” are called in turn to improve the results. Unlike parsers which short-circuit after a match is found, all the refiners run every time.
WikiRefiner.java
A ton of the content we watch these days is created by the streaming providers themselves. It turns out that there are folks who keep lists of all these shows on Wikipedia (e.g., this one for Netflix). The first refiner simply loads up a bunch of these lists and then looks at incoming search text for exact matches. If one is found, the channel is added to the model.
As a side note, the channel is actually added to the model only if the user has that channel installed on their Roku (as passed up in the “channels” query parameter). The same show is often available on a number of channels, and it doesn’t make sense to send a Roku to a channel it doesn’t know about. If the show is available on multiple installed channels, the Android UX will ask the user to pick the one they prefer.
RokuSearchRefiner.java
Figuring out this refiner was a turning point for the app. It makes the results far more accurate, which of course makes sense since they are sourced from Roku itself. I’ve left the WikiRefiner in place for now, but suspect I can retire it with really no decrease in quality. The logs will show if that’s true or not after a few weeks.
In any case, this refiner passes the search text up to the same search interface used by roku.com. It is insanely annoying that this API doesn’t return deep link identifiers for any service other than the Roku Channel, but it’s still a huge improvement. By restricting results to “perfect” matches (confidence score = 1), I’m able to almost always jump directly into a channel when appropriate.
I’m not sure Roku would love me calling this — but I do cache results to keep the noise down, so hopefully they’ll just consider it a win for their platform (which it is).
FixupRefiner.java
At the very end of the pipeline, it’s always good to have a place for last-chance cleanup. For example, TVDB knows “The Great British Bake Off,” but Roku in the US knows it as “The Great British Baking Show.” This refiner matches the search string against a set of rules that, if found, allow the model to be altered in a manual way. These make the engineer in me feel a bit dirty, but it’s all part of the normalization game — the choice is whether to feel morally superior or return great results. Oh well, at least the rules are in their own configuration file.
Hard Fought Data == Real Value
This project is a microcosm of most of the normalization problems I’ve experienced over the years. It’s important to try to find some consistency and modularity in the work — that’s why pipelines and plugins and models are so important. But it’s just as important to admit that the real world is a messy place, and be ready to get your hands dirty and just implement some grotty code to clean things up.
When you get that balance right, it creates enormous differentiation for your solution. Folks can likely duplicate or improve upon your algorithms — but if they don’t have the right data in the first place, they’re still out of luck. Companies with useful, normalized, proprietary data sets are just always always always more valuable. So dig in and get ‘er done.