The first entry in my 2025 book journal took a few more words than fit in that format, so adding them here. I’m always looking for more good reads; please share!
There’s a lot in Nexus about AI taking over the world, and Harari has some pretty impressive stuff to say about that. But for me the most novel part of the book is the framework of information flow that he develops on the way to that part. He’s not the most concise guy; my (surely flawed) summation is:
Human progress is characterized by a quest for truth and order. Truth helps us manipulate the world more effectively, and order allows us to live in larger and larger groups without killing each other.
Information is the raw material for both of these. But information is not truth and doesn’t necessarily lead to truth. E.g., information can be used by scientists to uncover new truths, but it can also be used to propagandize a population into collective beliefs — whether those beliefs are true or not.
There are two broad classes of societies: those that rely on an infallible higher power (e.g., the Bible or Stalin) and those that do not (e.g., Ancient Athens or the United States). The former prioritize order over truth; the latter rely on competing mechanisms of self-correction to balance the two.
Advances in information technology have made it ever-easier to share information, which has had a significant impact on which sorts of societies are more effective at balancing truth and order. These advances have benefited both democratic and autocratic models in different ways at different times
Artificial Intelligence is not a new information technology; it’s a new form of life that in many ways is superior to ours (primarily around information recall and pattern recognition) but with different motivations. E.g., it may not have the same regard for the individual that we do. AI participation will have dramatic and unpredictable impacts to how our societies, both democratic and autocratic, operate.
Harari does a remarkable job at building this all up with a ton of historical, real world examples. That alone is worth the cost of entry. His jump to AI taking over the world seems a bit disconnected — I struggled to see the thread leading from one to the other, until I looked at it in terms of fallibility.
We’re increasingly used to giving computers authority over important stuff. And this can come with negative consequences — Harari’s prime example for this is Facebook’s role in the violence against the Rohingya in Myanmar. In hindsight that picture is clear: (1) Facebook coded its feed algorithms to prioritize engagement; (2) outrage increases engagement: (3) the algorithm overwhelmingly picked inflammatory (and largely false) content to show folks in Myanmar.
This is a trap that anybody who has ever tried to “manage with data” will recognize — you get what you ask for. It’s not uniquely an “AI” problem at all; how many mid-level managers have received short-term kudos for firing essential employees in the name of cost-cutting? Or been promoted for hitting sales targets based on volume by giving discounts that kill margin?
The Myanmar/FB issue wasn’t AI, it was a poor metric coded by human engineers. But Harari is right that the more we consider AI as an infallible agent in society, the more its motivations (metrics) matter. And it’s a compounding problem — we are increasingly asking AI to create metrics that build on top of its underlying implicit values.
An example close to my heart is recruiting algorithms. It is a fact of history that many, many more men have been hired into software jobs than women (and thus, by volume, more successful engineers are men). If we ask AI to do a first screen of candidates, it’s for sure going to notice this and bias its decisions towards hiring men. Because we never explained that this bias was a problem, it simply does the job we asked it to.
Presumably we could solve this if we created the perfect set of underlying motivations in the first place — we could reward the AI during training for finding historical bias and compensating. That’s basically what we do as humans with diversity programs (maligned as they are these days), and we’ll clearly have to do the same with AI.
Bottom line: AI is no less fallible than humans — but it can screw up at a scale far beyond what humans can accomplish. Can we create the right checks and balances before AI becomes self-reinforcing and we lose control of the process? Because surely that will happen.
And of course the answer is, who the heck knows. But Harari does a great job making us think about it and face the reality — so worth the read. Highly recommended for both the setup/framework and the AI thoughts. Just be prepared to read a LOT of words.
Our world feels increasingly magic — I can have normal adult conversations with a computer; feel very much “in person” with my far-flung family playing VR minigolf; and sit back comfortably while my car drives me to California. Every once in awhile, we stupid, fallible humans build incredible, beautiful things.
But “magic” is also dangerous. When you rely on something that you don’t understand, you’re an easy mark. This annoys me every time I have to call in an expert to work on the house because I don’t know how to test (just a random example, not something that happened last month, but if it did happen, the guy was totally cool, I just don’t like being in that position) the pressure switch assemblies in my HVAC system.
Of course, the world is way too complex for us all to understand everything. But the good news is, complex things are just lots of simple things put together — and often understanding the simple version is good enough. If you know a bit about how real and fake neurons work, you can develop a pretty solid intuition for what LLMs are and aren’t good at. If you build a treehouse, you’ll gain some appreciation for how real houses work. And, the point of this article, if you code up a really simple genetic algorithm, full-blown evolution seems a little less supernatural (but a lot more awesome).
Evolution & Genetic Algorithms
The only honest knock on Darwin is just basic incredulity. “Come on, do you really believe that all the complexity of the human mind and body just spontaneously popped up, by random chance?” Often these are perfectly intelligent folks that believe evolution can do little things, like maybe select for sharper teeth in wolves — they just can’t buy the admittedly huge leap to a modern human.
And I get it, I guess. But the history of our species is basically just a long parade of thinking that things are magic or supernatural, figuring out that they’re not, and levelling up the magic another click until we figure that out too. So why are we always sure that this time is the one? Seems unlikely.
Watching simple evolution in action helps me buy that real evolution is comfortably up to the task of shaping the world we live in. And it turns out that building a digital environment in which to do that isn’t all that hard. It’s also super-fun, so let’s give it a try.
Genetic algorithms use digital versions of evolutionary concepts like crossover, mutation and fitness to iteratively solve problems. There are tons of ways to put them together; I wanted to start from scratch and build things up one step at a time. If you’re so inclined, I hope you’ll build and run the code yourself — it’s all open source and up on Github.
I should mention up front that I have basically no formal background in this stuff — I played with GA’s a bit in college but that’s it. So we’re truly exploring together here; apologies in advance if I do or say something stupid.
2D Cellular Automata
Before we get into the “genetic” part of all this, we have to create the world our evolving organisms will inhabit. For reasons that will become clear later, two-dimensional cellular automata provide a lot of advantages, so we’ll use that.
These worlds are two-dimensional grids of squares, where each square is “on” (black, true, or alive) or “off” (white, false, or dead). As time passes, the squares change value based on their current value and those of their neighbors (the cells surrounding them) according to some set of rules.
The most famous set of 2DCA rules is called “The Game of Life” — a surprisingly simple configuration devised by John Conway that generates satisfyingly rich behaviors. Life considers the cell itself and each of its eight neighbors (N, NE, E, SE, S, SW, W, NW):
If the cell is alive and
has 2 or 3 live neighbors, it lives on to the next cycle,
otherwise it dies.
If the cell is dead and has exactly 3 neighbors,
it comes to life in the next cycle,
otherwise it stays dead.
The only tricky thing about this is what happens at the edges of the grid, where there are no “neighbors” on one side or the other. Typically implementations “wrap” the grid around itself so that, for example, the neighbor to the west of square (0,0) is (dx-1,0) where dx is the width of the grid.
Life rules generate some pretty neat patterns — shapes that blink or oscillate, others that move across the grid, some that stay static, etc. The animation below shows a few common patterns in action; follow through to the Wikipedia page for an interactive version you can play with.
OK, back to business. Life rules generate some visually cool stuff, but they’re only one example of the tons of possible rule sets we could apply. That’s the crux of what we’re going to do here — use evolutionary processes to discover rule sets that accomplish something we’re interested in. The general approach is this:
Establish a goal state for the world (grid). A very simple example of this might be “All squares of the grid are black.”
Create a bunch of organisms (rule sets) at random.
Let each organism exist for awhile and then measure how close it is to the goal.
Kill off the worst and mate the best to replenish the population.
Repeat.
In this model, each “organism” inhabits its own “world” — there is no direct organism-to-organism competition for resources or space. Obviously this is a departure from natural evolution, in which organisms typically go head-to-head. But there is still performance-based competition for mates, so it works out.
We’ll see this again and again — there are infinite ways to tweak an evolutionary process. The real world is so wide, and so basically eternal, that nature just tries them all. We have to be a bit more judicious, but there are still a ton of different levers to pull.
Concepts and Code
Bitmaps, Edge Strategies and Neighborhoods
The Bitmapclass is the workhorse of this whole system. Space and speed are important, and we do pretty well at both by cramming the bits into an array of longs. Also as we’ll see later, the array-of-longs approach helps with some other evolution-y stuff.
This class also defines the EdgeStrategy enum, which defines how the class should respond when asked about a coordinate that is off the grid. We use the “Wrap” strategy almost exclusively, but the alternatives might be useful in specific cases.
The Neighborhood class encapsulates approaches to identifying the relevant context for a particular square in the grid. The rules of “Life” which we saw earlier use a Moore Neighborhood, which is basically the 3×3 grid centered on each square. The Von Neumann Neighborhood is also common, which excludes the diagonal corners of Moore. There are others as well.
The neighborhood defines everything that a square “knows” about its environment at a given point in time, so it’s obviously super-important to the learning process. We’ll see this in action in part two of the series.
Organisms, rules and “DNA”
Unpacked, real DNA is basically a sequential chain of four nucleotide bases (A, C, G and T). In order to apply genetic algorithms to digital organisms, their digital DNA must also be representable by a chain of primitive building blocks.
Digital DNA must also be resilient to random mix-and-match operations during reproduction. A single mutation in an organism’s genes can be:
Irrelevant. Much of our DNA is “non-coding” and a mutation within these regions may be pretty much unnoticeable (ok it’s a bit more complicated than this, but close enough).
Advantageous. A mutation may make the organism more fit for its environment — maybe the shark’s teeth angle back a little more to hold onto prey.
Disadvantageous. Perhaps it makes the organism unable to create a particular enzyme, like the lactase that helps us digest dairy products.
Catastrophic. A mutation may render the organism completely unviable due to a structural problem that stops the DNA from functioning at all.
Evolution doesn’t work very well if #4 happens with any real frequency.
This is a major design challenge for GAs, but manageable for our particular problem. The NeighborhoodRulesProcessorclass uses our array-of-longs Bitmap approach to create a sequence of bits that can be easily manipulated, perhaps to advantage or disadvantage, but without damaging their viability.
This next bit is a little hairy; bear with me. Or just skip to the next section, understanding that our rule sets are represented by a resilient array of long integers. Here goes. Neighborhoods are stored as arrays of relative coordinates: e.g., (0,0) is the target square itself, while (-1,0) represents one position to the West. Neighborhood Rules assign each of these relative coordinates to a bit in an integer. For a Neighborhood that looks at X squares, this results in 2x possible integers: 32 for Von Neumann, 512 for Moore.
The “outcome” for each of these integers is either “black” or “white”, which we represent using a one-dimensional bitmap indexed on the integer itself. The array of longs underlying this bitmap is our DNA, which is pretty cool. Any bit in the rule set can be altered and we will still have a viable outcome — maybe better or worse, but never catastrophic. Sweet.
Fitness
Once our population of organisms has run for awhile, we need to asses how “well” each one did, so we know who should die off and who should hook up.
This is the job of the Fitnessclass. The simplest type is MostOn, which simply counts the number of black squares and reports it as a fraction of the total. The best possible fitness score in this case is 1.0 — solid black.
Fitness can really be anything measurable — in part two we’ll look at vertical stripes, alternating black and white one-pixel wide vertical lines. We’ll also see how different ways of measuring Vertical Stripes fitness can make a huge difference.
Selection
The Reproductionclass sorts the population by fitness and uses that ordering to decide which organisms should reproduce (the best two-thirds) and which should die off (the bottom third).
The reproducing population is paired up using a strategy defined in the PairingTypeenum. The default is “Prom,” which pairs the organisms ranked #1 with #2, #3 with #4, and so on. Random mixes this up so anyone can pair with anyone. There are other ways to do this too — March Madness-style bracket seeding, anyone? It also might be interesting to change the proportions and allow some or all of the winners to have multiple offspring.
Again, this isn’t exactly the way it happens in real life. But it’s close enough — and we get more levers to play with along the way.
Crossover and Mutation
The last bit we need to code up is the actual reproduction between two organisms — combining the DNA of each parent into a brand new, novel offspring. This happens in two steps:
Crossover takes subsections of each parent’s DNA to create a new sequence by picking a random set of indices to be “swap” points. Bits are taken from parent #1 up to the first index, then we start taking bits from parent #2 until we hit the next one, we swap again, and so on. The number of crossovers is random but subject to a configured maximum.
Mutation takes the new DNA strand and twiddles a few bits at random, again subject to a configured minimum and maximum rate of mutation.
The new organism takes the places of one that didn’t make the cut, and we start the whole process over again. If things go the way we hope, maximum and average fitness for the population goes up and up until we, seemingly by magic, have found our answer.
Putting it all together: Evolving a blackout
Our first run will be a 25-cycle evolution of 200 organisms trying to turn all squares in their environments black. Each cycle will run for 200 iterations over a 100×100 grid initialized with a random pattern. (Fun fact: it’s a very poor choice to start with an empty (all white) environment for this challenge — can you guess why?)
We’ll use the same Moore neighborhood as we did for Life. We’ll use Prom-style pairing, allow a maximum of 10 crossover points, and mutate at a rate between 2.5% and 7.5%. This mutation rate is way higher than in nature, and while it can create some chaos, it also introduces novel configurations more quickly, which can reduce the number of cycles required to progress.
…and it’s pretty cool! Now to be clear, this is an easy task. The single rule “no matter what is in my neighborhood, turn me on” will accomplish it in a single iteration. But our organisms didn’t know that. They each started with a totally random set of rules, and all we did is measure how that random set did, pick the best and mix/mate them together, and try again. This graph shows the best, worst and average fitness scores over each of the 25 cycles; by cycle 17 we’d found rules that seem to work perfectly:
Another fun way to look at this progression is to look at the best-performing result at key points along the way:
We’ll see more of this next time, but you can also get a sense for the different strategies that can emerge. In cycle 18 for example, there are dots and lines and blobs and all sorts of mechanisms at work.
Success is Usually Messy
The last thing I’ll call out from the blackout run is that evolutionary success is rarely what you’d expect. I pointed out above that you can achieve a blackout in one iteration with a single rule — but that’s not what our evolution produced.
Moore neighborhoods generate 512 individual rules, and that’s just hard to look at. So I ran the blackout evolution again using a Von Neumann neighborhood of 32 rules. Results for that run are here — similar except in this case we got really lucky and one organism hit perfect fitness on the very first run.
Anyway, the rules for the winning organism in this run look like this; the top section are rules that turn their cell white, and the bottom turn their cell black:
There are significantly more black rules than white.
Only four rules (highlighted in red) make the grid “whiter” — all others are either neutral or black.
Progress reinforces progress — ignoring the center value, all of the rules with three or more black inputs have a black outcome.
Run over 200 iterations, these rules are basically guaranteed to get us to a blackout. But it sure is a roundabout trip compared to the “optimal” rule (I’ve put an animation of our winning rule going through just 12 iterations at the end of the article). However, it’s important to understand that, given our fitness rules and environment, our evolved rule is exactly as good as that “optimal” one. As long as the blackout was attained by iteration #200, it did the job perfectly. Nothing about our world indicated that speed mattered — only the final outcome.
OK, that’s enough for this session. We’ve done a lot — learned about 2D Cellular Automata, wrote code that lets us mimic evolution in digital form, and even saw the first glimmers of some pretty cool outcomes. Next time I’ll get deeper into the weeds so we can really see how this machine ticks. There are just unlimited cool things in the world.
My last article was full of nostalgia for the lifetime of hacks that have shaped my life and career. I touched on the real bad guys too, but basking in the warm glow of a CRT it’s easy to forget how relentless the ugly side can be. They are always, always “on” — and they only have to beat the good guys once to do a ton of damage.
We talk about network security using physical analogs — doors and keys and alarms and such. And that’s fine as far as it goes, but it completely underplays the insane scale of attacks happening on the Internet all day, every day. A more accurate picture is the zombie horde surrounding the mall in Dawn of the Dead, probing 24×7 for any vulnerability.
A quick illustration. I keep a server in the Azure cloud that I use to test early versions of an app I’ve been working on the past few months. I keep this machine turned off 95% of the time, spinning it up only when I want to preview a new feature or do a demo.
Last night I flipped the server on for about six hours. Before shutting it down, I took a quick look at the request log and despite myself I was again struck by the sheer volume of attacks. Somehow within ten minutes of powering up, the script kiddies found my server and started rattling the doors and windows. A small sampling taken from hundreds of attempts:
These are basically the equivalent of checking for a key under the welcome mat, flower pots, above the door jamb, or inside fake garden rocks. They’re files that may contain sensitive information like passwords, and are commonly hosted “accidentally.” Either they shouldn’t be on a production server at all, or the hosting web server is mis-configured to allow access. There’s a massive list of these — it’s really easy to slip up when deploying a large project.
These are all attempts to coerce my server into running code provided by the hacker. Sometimes the problem is debugging code deployed to production accidentally, kind of like the open secrets issue. More often these hacks exploit SQL injection or buffer overruns; the web server receives data from the user and accidentally executes it as code. Of course, if I can convince you to run arbitrary code on your server, you’re hosed.
3. Beacons and secondary attacks
/aaa9
/aab9
/alive.php
/t4
/teorema505?t=1
Once a hacker breaks into a machine, they’ll typically install backdoors or other software that makes it easier for them to keep control. One of the most popular apps for coordinating this is Cobalt Strike, which ironically was created as an “ethical” hacking tool to help good guys find vulnerabilities.
The first two URLs are “probes” checking to see if my server is running Cobalt Strike. If so, it’s probably in control of other hacked servers — basically bad guys trying to take advantage of other bad guys, or possibly good guys being sloppy with their tools.
Diversity helps!
Each of these attack types is interesting in its own right. But the really scary thing is that they represent just a fraction of the bad dudes hitting my server over only a few hours. It’s relentless — I’ve seen estimates that suggest that around 25% of all Internet traffic is hacking scripts (which doesn’t quite top porn’s 30% but is still pretty terrifying, go humans).
The one positive thing that sticks out is that — just like in culture, public health and farming — diversity helps. The hacks I catalogued were targeted at specific products: Microsoft Exchange, PHP, Git, Apache, Cobalt Strike, Cisco, Fortinet and more. Because I’m not running these, the attacks are impotent.
Of course, diversity isn’t the most efficient model of the world — many folks think I’m a little weird for running my own embedded web server. But it’s amazingly protective. So there’s my plug for robust anti-trust action in the tech industry.
In any case, just a glimpse. Keep your systems updated and please, for the love of God, don’t click that email link.
I just finished re-reading my copy1 of The Cuckoo’s Egg, Cliff Stoll’s detailed account of the German hacker that waltzed through the academic and military proto-Internet back in the Eighties. Reading this stuff brings me back in time, the way world events and other touchstones do for normal people. Almost a half-century of hacking history! Insane.
Disclaimer: While the culture has been extremely formative to my life, I was never a serious hacker. There were a lot of kids like me — fascinated by technology, curious, and a little drawn to the idea that adults didn’t like what we were doing. I certainly don’t recommend breaking any laws; there’s more than enough cool stuff in today’s world to explore without having to be a bad guy.
My folks got me a TRS-80 Model I for my ninth birthday. My own computer, in my own room — it was absolutely unheard of, and while my parents were pretty great in a lot of ways, it’s not much of an exaggeration to say that this was one of the most consequential things they ever did for me. It was really mine — when I wanted to wire up a snooze button for the alarm program I wrote, I cracked that sucker open and soldered a switch right onto the board (with 16-gauge speaker wire no less). I can’t believe they let me do that stuff.
I learned to write BASIC programs by transcribing code out of magazines and finding my typos. I was unbeatable at whatever that car racing game was called. I tried (unsuccessfully) to sell my own game “Arrow Attack” by placing a tiny ad in Creative Computing. It Was The Best.
Unfortunately, the Model I was discontinued pretty quickly because it emitted an illegal and possibly dangerous level of radio interference. Even this was kind of awesome — I had a few games that manipulated the signals to broadcast sound effects to a nearby AM radio (they sounded like this, try harder 5G).
The 80s: Phreaking and WarDialing
I continued to write code through middle school and high school, but was really more enamored with networks and modems. Back then the phone company still “owned” every piece of equipment connected to the network, and it was illegal to use a modem without getting authorization. They claimed it was protect their lines from damage, but really they were just monopolistic a**holes, so we ignored that. The AT&T breakup in 1984 paved the way for all kinds of awesome stuff, not the least of which was the Sports Illustrated Football Phone.
Anyways. “Phone phreaking” — using tech to control telephone lines and billing — had already been around for years when I learned about it, and some of the exploits were already being patched by the Baby Bells. But enough were still active to make things fun. For example, most payphones “told” the main office about events like coin insertions by playing specific audible tones — so if you (theoretically of course) had a machine to generate those tones, you could connect calls without using actual coins.
Phreakers maintained a huge list of “boxes” that could perform various feats. The only one I ever built was a “black box” — really just a resistor activated in-line with the phone. When mechanical switching equipment connected a call to start the phone ringing, voltage on the line was pretty high. Picking up the phone dropped that voltage, which was detected at the substation and used to start billing. Deploying a black box would reduce the voltage just a bit — enough to stop the ringing but not enough to trigger the billing event. Since the line was already connected, you could talk away and never get charged.
The only trick about a black box was that it worked on the receiving end of a call — so it was primarily used by folks hosting “BBS” software, enabling users to connect inbound for free. I spent a lot of time connecting our computer (by then a Compaq Luggable my Dad used for work) to these “Bulletin Board Systems,” messaging with folks around the country and world.
Unlike today’s always-on social media, a BBS was more like a drop box. Users would dial directly into the BBS via receiving modems connected to one or more dedicated phone lines. You’d read and respond to messages, upload and download files, then disconnect so somebody else could use the system. There were hundreds of these online in the mid 80s; I’d sit at the computer into the wee hours of the morning, listening to WAAF and bopping from one to another.
The currency of BBS users was typically software or “text files.” I was a fan of text — thousands of people (of widely varying intent and ability) wrote about everything: science fiction, sex, hacking and phreaking, anarchy, radio, survival … everything. Seriously, check out textfiles.com, they’ve created a huge archive and you can get lost in there for years. So much garbage, but also an amazing repository of decentralized, censor-free, citizen-created knowledge at a time when there Was No Internet. Intoxicating, especially for a young teen in the boring suburbs.
Small homebrew BBS’s gave way to commercial services like The Well that used subscription fees to support more phone lines — enough for real-time conversations between users. And those in turn gave way to the big boys like Compuserve and AOL. But man, those early days were fantastic.
In parallel with all of this, the Internet was quietly being built at academic and military computing centers around the world. Most of these systems could be accessed through modem connections as well, and from there a user could connect around the world.
This was the world of The Cuckoo’s Egg, and a ton of popular culture and media-driven fear about espionage and all the worries that come with every new technology. The anthem of my personal circle was WarGames; there was nobody — nobody — as cool as David Lightman.
Modems connected to the ARPANET/MILNET were a hot commodity, and (thanks to WarGames) we knew that the way to find them was a WarDialer. I wrote my own (in BASIC of course) which scanned every phone number in the local calling area around Lexington, MA — special because it searched numbers out of sequence, an attempt to evade detection by the phone company. Hello, Route 128.
Early 90s: First Winter
I really learned to code during the tail end of the 80s and early 90s. Despite a bunch of time writing in BASIC, I didn’t really have a clue about the craft that is software development until I got to Dartmouth. A computer science department small enough to know everyone but big enough to go deep, a Mac for every student, and fully-networked dorm rooms! And after that, my early career at Microsoft kept me pretty heads-down for a few years …
… which was a good thing, because it was a pretty lousy time to be a curious hacker. There were some interesting trends for sure — buffer overruns, viruses and worms all involve neat technical problems. But mostly it was a time when the a**holes took the wheel.
Chaos seemed to be the point. Hackers vied to see how far their viruses could spread and made sure their names were attached. Sometimes they caused damage on purpose; more often they just wrote bugs and screwed up systems by mistake.
I’ve always been annoyed by the flak Microsoft took during this time. Windows always took the blame, but it was the preferred target because it was the most popular operating system in the world, and because it was a platform for thousands of independent developers building their own businesses. Sure the company could have reacted more quickly, but everybody was caught flat-footed at first. Ah well.
Anyways, after a pretty nasty arms race, the platforms figured out how to release patches quickly, users learned to be more careful, and things settled down a bit as we entered the second half of the 90s. Then along came the next twist.
Late 90s and Early 00s: The Internet Emerges
The Internet bubble was an incredible ride. All of a sudden, everything was a website. People were actually using the Internet to buy things — with real money! — but the technology was in its infancy and nothing was off-the-shelf.
At drugstore.com (a great example of the business plan “What if we took blank and put it online?”), we built one of the very first large-scale eCommerce experiences. Shopping carts, online promotions and coupons, affiliate programs, secure payments (you could even USMail us a personal check!), live inventory management, automated replenishment, prescription refills (admittedly mostly for Viagra and Propecia), contextual advertising … The list was long and fun and we were breaking new ground every day. What a rush.
And of course, all that brand new technology was fertile ground for new hacks. A few examples:
While almost nobody ever used this, the Windows NTFS file system actually allowed one file to contain multiple “streams” of data which were addressed by using the format FILENAME::STREAMNAME. The “default” stream was called $DATA, so by fetching a page like http://somesite.com/myexecutablescript.asp::$DATA, you could convince IIS to return source code. This code often contained passwords or other secrets helpful in digging into a site.
SQL Injection hacks were everywhere; almost nobody fully protected against them in the early days.
Silly and simple, for some reason we thought that hidden urls named things like /test and /admin would actually stay hidden. Search crawlers also found documents nobody ever meant to be public; to this day searches like passwords filetype:xls routinely return sensitive data.
Identifiers like order numbers and user identifiers were often issued sequentially, very helpful in accessing information beyond your “allowed” scope.
Most of these were notable because they came and went so quickly; everything was moving so fast that open discussion truly was a public service. And of course the pace of innovation slowed when the money evaporated, which gave the second wave of sites time to catch up.
10s and 20s: Second Winter
During the last decade criminal hacking activity has gone nuclear — organized crime and state actors have figured out just how cheap and powerful hacks can be. Sadly, they’re not generally even very interesting — mostly phishing-initiated attacks that convince somebody to disclose credentials or other sensitive information, used for data ransom and identity theft. There’s nothing clever about social engineering; it’s just ugly and wrong.
In the less-purely-evil arena, the “Internet of Things” has been having its day in the hacking sun. It’s the same old pattern — rapid innovation around digital smarts in our appliances, cars, healthcare devices and homes has outpaced effective security. The good news is that we know how to catch up, and the ecosystem is doing so pretty reasonably.
Radio-based devices are being exploited as well. One of the most interesting (but unfortunately cheap and lucrative) hacks is the keyless entry amplifier. Many cars now automatically unlock as you approach with your key fob. There are a few ways the unlock can be initiated, but the basic idea is that your fob emits a low-power radio signal with a unique security code2. The signal is only strong enough to reach a few feet, so your car “hears” it when you get close and can respond by unlocking the doors. If a hacker can get physically near to your fob (say outside a window near your home office, or next to your purse at a coffee shop), they can amplify the fob signal to a receiver near the car. This amplifier doesn’t need to understand the codes, it just needs to relay the signal from the fob to the car and … poof!
So what’s the verdict?
For better or worse, new technology goes hand in hand with ways to break it — and there are always bad guys ready to take advantage. The world of “white hat” hacking can be sketchy and fraught, but I think it’s proven itself to be an essential part of the innovation cycle — pretending the holes don’t exist is not a recipe for success.
Lots of folks disagree with this — to paraphrase Stoll, we don’t thank a burglar who takes advantage of an open door. That’s a super-legitimate perspective, and there’ve been many instances where “ethical” hackers accidently wrote their own bugs that went disastrously wrong (e.g., the 1988 RMS worm). So where’s the line?
It’s hard to say, and certainly not one easily parsed by hormone-addled teenage brains! But there’s no question that the discoveries, problems and solutions behind almost a half-century of hacks turned me into the developer that I am today, so it ain’t all bad. I try to break my own stuff, and count coup on my friends when I find flaws in theirs. The coolest stuff rarely sits in the middle of the road.
1. Back in the early 1990s I built a little toy for the Macintosh called Mouse Odometer, a background app that measured mouse travel in miles. MO was shareware with a requested donation of $5; sometimes folks would send other stuff instead. Cliff Stoll sent me a copy of his book!
2. The back and forth here is usually more complicated; constantly broadcasting a signal drains a fob battery pretty quickly. Instead, usually the car is constantly broadcasting a low-power “wakeup” signal that causes any of the fobs in the vicinity to start doing their thing. Passive RFID technology and the transfer of power by radio is basically magic.
It’s lumber season at our place on Whidbey Island — winter tides and storms carry tons of driftwood to the back yard. Mostly firs that have fallen off the high banks or escaped from log booms, but lots of Alder, Maple, Cedar and old construction timbers mix it up.
I’ve got stacks of this stuff slowly drying out in every corner of the property — each piece has character and history and basically shouts what kind of project it wants to be. Bowls, gates, benches, boxes, vases, ornaments, wall art, clocks, lamps, tables … you get the idea.
There’s just something really neat about physical “stuff” that connects with memories, places, times and people. So I always try to be on the lookout for ways to create things with meaning for other folks as well. I just finished two of these projects, one for each of my kids.
1. Catamount Center, Colorado
My son spent many years at the Catamount Center, an environmental education center in the mountains outside of Woodland Park. He was a student there, then a fellow, and eventually the Director of Education. He’s moved back to Washington now but rescued a few logs from the Catamount firewood pile before he left. I think it’s Limber Pine or Blue Spruce, but hard to be sure.
C requested a side table — the light color of the wood fit well with his (ok, his girlfriend’s) modern vibe but the soft wood definitely needed some help to serve in that capacity. Let’s go.
First job was to cut a few slabs — lots of ways to do this (and some cool rigs online), but my go-to is simply to draw out some guidelines and freestyle it with the chainsaw. They’re going to need cleaning up anyways, so perfection at this stage isn’t worth the trouble.
Next up, rough planing to shape and then a bunch of dry time. It is hard to overstate how much this stage tests my patience; even at just a couple of inches thick, it took weeks in the humid PNW for the moisture content to drop enough to move on. More planing to take out the inevitable warps, and a lot of sanding.
The table is made up of two slabs joined with dowels along a flat cut. I don’t love the seam here but did my best. Someday I’m going to break down and get a jointer; I’m sure L won’t mind if we have to park the car outside the garage! This left two live edges, and I cut the others at about twenty degrees. More sanding.
Finally ready for some tabletop epoxy. This stuff is really nice for a side table — no coasters needed and plenty hard enough to protect and stabilize that soft pine. I even tucked a little picture of Susie (C’s dog) up at Catamount into the corner. My go-to adhesive cork along the bottom and some black pin legs (levelling four legs is always a joy) and it was good go to. A nice memory of a place that shaped a lot of C’s life through his early twenties!
2. Burbank Bungalow, CA
Burbank is full of cool little homes built during the studio era — a similar feel to the craftsman neighborhoods north of Seattle (minus the hills). My daughter bought a place down there a couple of years ago, and she is the proudest homeowner you’ve ever met.
Unfortunately, some necessary gas line work killed a couple of beautiful old lemon trees along the side of her house, and before replacing them with seedlings she saved a few branches for me. I wasn’t sure what to do with these at first, as they were a bit too small for a vase or bowl. I tried turning some tulips but wasn’t a fan of the outcome.
The lemon wood was really, really beautiful, both the stripey bark and the brilliant yellow inside. After playing around a bit more, I decided to try my hand at carving three little birds for a display piece. I’m not much of a 3D artist, but with the help of a pattern (hat tip North Idaho Carver) and my scroll saw they came out pretty ok!
The idea here is to start with a rectangular block (milled out on the band saw) and then transfer “top down” and “side view” patterns onto two sides. Scroll cut one of these patterns, tape the block back together, turn 90 degrees and cut the second one. This leaves a rough-cut version of the bird which can be carved and sanded to final shape. I tweaked sizes and shapes on each one to make an interesting set — kind of in love with this process!
A half-cut of another branch made a great base — hopefully the polyurethane I applied will keep the bark attached! I just used neutral paste wax on the birds themselves, which did a nice job deepening that awesome yellow.
It makes me super-happy to think of both of these projects living with my kids and reminding them of their respective journeys. Wood is such an amazing material — beautiful in life and beyond. But that’s enough sappy stuff for one post. Until next time!
TLDR, drag this link to your bookmarks bar: explain. If you select medical-related text on any page and then click the link, it will open up an “explain” window with an AI-driven translation. Alternatively, you can just visit the site at https://explainmynotes.azurewebsites.net/.
Every day I seem to get just a little bit older. My folks too. Not a bad thing, but it does inevitably mean more time spent trying to navigate the clown show that is American Healthcare. Sometimes things are simple, and sometimes they’re little mystery dramas with House or Doc Martin trying to figure out what’s going on.
By now, most of us have gotten used to using patient portals like MyChart to keep track of our care at various providers. Lab results and clinical notes show up in near real time and — thanks to years of policy pressure — are quite comprehensive. (to wit: when I had appendicitis earlier this year, my wife at home texted me the diagnosis before anybody in the ER came to let me know what was up.)
Access to these primary sources is invaluable. But clinical notes are also full of jargon, shorthand, codes and concepts that very few of us understand. Take for example this short snippet from the surgery notes of my appendicitis visit:
I attempted to bring omentum to sit over the anastomosis, but the omentum was fairly short and there was no easy reach.
I read this shortly after coming out of anesthesia — something she tried to do didn’t work. Is that bad? Should I be concerned? Luckly, Dr. M is pretty awesome; she explained that the omentum is a layer of fat that protects organs in the abdomen, and they like to “drape” it over surgical sites to aid healing by enhancing local blood flow. Somehow despite my notable beer belly I didn’t have enough fat to make this work, but it’s not a big deal. Case closed.
Unfortunately, not every provider is a great communicator like Dr. M. And even when they are, appointments are so short and far-between that there’s rarely a good opportunity for questions like this. That’s why I wrote explain my notes.
Clinical Notes, explained by AI
explain my notes takes advantage of two pretty neat technologies: SMART on FHIR for data access and ChatGPT for helping to interpret the notes. Currently it’s set up to connect to providers using Epic MyChart. In a nutshell, it works like this:
Visit the site, read the terms of use and pick your provider.
Log in at the provider’s patient portal and approve the connection.
Pick an encounter to see a list of associated documents.
Pick a document to view its contents.
Select any text in the document and choose “Explain Selection” to pop up a window that shows the original and “explained” text side by side:
And that’s it! You’ll need to authorize the app each time you use it, because Epic doesn’t permit long-lived tokens for “automatic download” patient applications. Ah well.
Caveat 1: The ChatGPT API isn’t free — if I’m surprised and the app gets a lot of direct use, I may have to figure out how to offset those costs. For now I just hope folks try it and that it’s (a) helpful and (b) inspires others to build on the idea.
I’ve already written a bunch about SMART and why I think it’s so valuable, so I won’t repeat myself here. But this is the first time I’ve written a SMART app for patients, and there were a few interesting nuggets worth a mention:
Standalone Launch
explain my notes uses the “standalone launch” model. With a provider app, a huge part of the benefit comes from living within the context of the EHR — it gets you single sign-on and provider/patient context and feels seamless in an environment where providers are already spending much of their day. It’s not the same for patients; a dedicated site that can explain its function and then “connect to” the portal makes good sense.
Epic Automatic Download
The super-cool thing about patient-facing apps is that you don’t need to “register” them with each individual EHR. Instead, the EHR vendors maintain provider lists and automatically enable connections when authorized by the patient. It’s hard to overestimate just how great this is — back in the day, we had to arrange to connect HealthVault to each and every provider that wanted to work with us.
Careful, though! Automatic download comes with conditions, and they are not immediately obvious (Epic’s conditions are documented behind a free login). “Refresh” tokens aren’t allowed; only certain data types can be accessed; no “write” operations are permitted, etc. My first cut at the app didn’t meet the criteria exactly, and it took me awhile to figure out what was going on.
PDF and CCDA Content
Many notes are stored as HTML or text. Encounter summaries, though, are often stored in “CCDA” format — an old-school XML standard. XML needs to be translated into HTML for display in a browser, and while there is some solid open source code for doing that, the generated HTML doesn’t always display nicely within a larger web page. I was able to tweak it for my purposes; the altered stylesheet is available per the original’s open-source license terms.
PDF content was also a challenge to display so that it both (a) looks correct and (b) makes the selection available for sending to ChatGPT. I ended up doing a server-side translation using pdftohtml, an old standby that still works surprisingly well.
Explaining notes: ChatGPT
I think it’s clear that generative AI is going to be a seriously Big Deal — combustion engine and Internet big. But it’s still very early days, and it’s hard not to be annoyed by the seemingly endless garbage “applications” being churned out by hype-riding VC-funded bros. I get that — but bear with me.
Generative AI (specifically ChatGPT for us) is pretty amazing if you think about it as your well-read, smart, eager-to-please friend without any formal training and a fear of being wrong. People like this are super-useful, because they’ve probably come across information that you haven’t, and can be great “translators” of jargon and other specialty content. You just have to take what they say with a grain of salt — a little fact-checking goes a long way.
The ChatGPT “completions” API is pretty simple — it takes an array of input/questions and returns answers in markdown format. There are a few knobs you can turn, but that’s basically it. “Prompt engineering” is a weird concept, much closer to social engineering than code. The current “setup” prompt for explain my notes is this:
You are a medical professional that explains clinical notes and other medical text using terms and language that an average American adult without medical training will understand. Minimize the use of jargon. Your responses should not be notably longer than the original text. Also please include up to three Google search links targeting the key topics you find.
The “Google search links” part here is the most interesting. I initially asked the system to return “up to five links that would be helpful for further research,” but it turns out that ChatGPT is terrible at this, and is actually known for simply making up gibberish URLs. I’m not sure why this is the case; apologists claim they’re just stale links from old training data, but it’s way more than that. Restricting the links to Google searches seems to work pretty well.
And I guess that’s it for now! Please give the app a try — good test data is hard to come by and so I’d appreciate any and all feedback or bug reports. Until next time…
For reasons that are both complex and silly, I am now the proud owner of a twenty-foot shipping container. It’s a “one-trip” box, having made a single voyage across the Pacific, probably from China carrying Trump merch stamped “made in America.” In any case, it is now safely ensconced in my hillside, destined to be a storage shed and/or adjunct workshop. I’ve definitely outgrown the garage.
Outfitting a container turns out to be a super-fun project (not counting the second coat of “duckboat drab” paint I have to apply later today as phase one of Operation Camouflage). The company I bought it from blew a layer of foam insulation on the walls, so my first interior job was to build a wood frame onto which I could hang shelves, hooks, lights, pegboards and whatnot.
Non-structural framing is fun work; it moves quickly and delivers big, solid walls in just a few hours. It’s also easy to learn, and can be done exclusively with relatively cheap 2×4 lumber. You can even do it solo, although moving wall sections on your own any distance is a bit dicey (thanks Connor). But like everything in this world, the details make all the difference.
I can’t say this enough: the details make all the difference. There is more to everything in this world than first appears, and that goes for simple framing jobs too. Take a look at your tape measure — do you know why every 16” interval is highlighted? It’s because 16” is the standard distance between wall studs — those highlights are great time-savers as you mark top and bottom plates.
Or consider the humble 2×4 joist hanger, a little metal bracket that makes it easier to attach joists to wall segments. “Joists” run in parallel along ceilings or floors to provide strength and rigidity — my internal structure isn’t attached to the container at all (except a few screws into the floor), so the joists keep the walls from falling down. At first glance it’s a pretty simple little widget:
Four screws (or nails) attach the hanger to the wall.
The joist slides vertically into the bracket.
Two screws secure the joist to the bracket.
Easy peasy lemon squeezy, right? But wait, there’s more to learn. First of all, keeping the bracket correctly aligned as you screw it in can be an annoying challenge, especially if the wall is already standing and you’re on a ladder. See those little pointy tabs on either side of the bracket? Those are called “speed prongs,” and by hammering them down you can temporarily hold the bracket in place, exactly where you want it.
And take a closer look at the two screw holes that hold the joist in place. You’d think they’d be symmetrical, but they’re not — they’re just slightly staggered. This is because a 2×4 is pretty thin; if the holes were aligned the screws would run into each other.
This stuff is pretty obvious in retrospect, but the value is easy to miss at first glance. Without context these features might even seem kind of stupid — needless complexity that just makes the bracket more costly to manufacture and package for shipment.
Yeah, it’s another software analogy.
There is always a reason that things are the way they are. One of my biggest peeves is an engineering leader or manager who walks into an existing organization and decides that everything needs to be rebuilt from scratch. There are plenty of excuses: the existing code is spaghetti and hard to maintain, it’s built on obsolete technology, it didn’t keep up with the needs of the business, blah blah blah. All horsesh*t.
I mean OK, it’s not that these arguments might not have merit; it’s just that they aren’t really why people start from scratch. In truth,
They are too lazy or incompetent to understand the current state, and/or
They are trying to establish their own empire in their own image.
The reality is that even the “craziest” operational software is what it is for a reason. It has history. The company wasn’t populated by idiots doing stupid stuff for kicks. If you don’t understand the why — and often even if you do — your “reboot” is going to fall flat on its face.
The problem is that, just like speed prongs and offset screw holes, many crucial details don’t make sense or are simply lost when viewed without on-the-ground context. Everything looks simpler when you don’t get down and wallow in the (I know) details.
I just watched this happen again, in slow motion over (I kid you not) three and a halfyears. Within weeks of taking over, a new leader declared the company’s core operational systems not worth saving and started a reboot. Task forces were created, user interviews happened, vendors pitched their solutions head to head, much enthusiasm was expressed, and ….
… not only did the old systems carry the load successfully throughout the “transition,” they will continue to do so indefinitely because the reboot was just straight-up abandoned. All of it. Even worse, the other day I happened to be chatting with an executive who actually said (with a stunning lack of self-awareness), “of course we’ll have to figure out how to replace it somehow.” I mean come on people.
(Before you start telling my why your reboot was the right choice — I get that there are exceptions to every rule. I’ve had to start from scratch a few times myself. But take a long, hard look before you feel good about your choice; it was almost certainly a net loss.)
So what, just never do anything?
Of course not — needs change over time, and we’re always learning — our best design yesterday is almost certainly worse than our best today. It’s just that evolution, not revolution, is the way to go.
Software evolution (or more cleverly the tin-man paradigm) replaces a system in small bites, one step at a time. Eventually you’ll have rebuilt it all, and then it’s time to start the cycle again. In a well-functioning organization this process never ends — you’re always working on the next-most-important change.
Each update should be small enough that you can assess what the existing code is doing in the real world. All the edge cases, all the workarounds, all the accommodations. This is the really important bit — keep the scope small enough that important (yes) details don’t get lost in sweeping user stories.
If you’re starting with a monolithic system, breaking out little bites can seem super inefficient. You’ll probably have to build “throwaway” integration code, something that’s tough to swallow in a world of limited time and resources. But it’ll pay off in the end, I promise — and with the added benefit that if something goes wrong, you can retreat to the known quantity without too much fuss. It may even get you to that elusive “microservices” architecture everyone is so hot and bothered about.
None of this is rocket science — but again and again, the siren song of a clean slate sucks us in. Don’t let that happen! Just remember:
Everything exists for a reason. It was built by people just as smart as you.
Evolve systems in small bites. It’s the only way to understand what you’re improving.
Sweat the details. True in everything, and certainly here.
And look, if you want to design a better joist hanger — go for it! Just don’t forget the speed prongs — thumbnails everywhere will thank you.
Back in the nineties, recruiting was part of my job as a developer at Microsoft. The bar was high on purpose, and we were proud of it. A tough interview process is good for a lot of (mostly obvious) reasons, but for me the most important was that it created an assumption of competence at the company. If you were in the building, you probably weren’t an idiot.
As a person who collaborates best through, let’s say, “vigorous debate,” this was unbelievably liberating. If an idea was stupid, I could say that — and folks could say the same to me — and except in some very rare cases it didn’t get personal.
People are always surprised when I tell the (admittedly hilarious) story of Bill and the Gunshot Wound, but that was the path to success at Microsoft. Take a position and defend the hell out of it — if you win against all comers, you were probably right. I loved it, and it mostly worked.
And it’s exactly because it worked so well that it took me years to recognize that we (I) could do even better. Microsoft in the 80s and 90s conflated a particular personality type with intelligence and success. It just so happened to be my personality type, and I spent those early years blissfully working with a bunch of copies of myself. Building tools that worked the best for people like me.
Huh.
Now before we go too far here, let me be clear: I don’t abide stupid. Stupid kills and stupid loses. But it turns out that being stupid is mostly a personal choice. A half century of watching people has taught me that “everybody is good at something” is actually true — success comes down to taking ownership for figuring out what that is and working to become great at it. Stupid is just lazy.
Anyways, sitting here I can play back in my head dozens of real, brilliant individuals whose diversity and alternate perspectives made me and my products better — and sadly, a few (especially in my early years) that crashed out because I was unwilling to adjust my own behavior to optimize theirs.
I like to believe that I’ve gotten better at this year over year — but there is one person who probably doesn’t have a clue just how much she changed my life. She is extraordinarily smart, with a remarkable sense of personal responsibility and empathy. We built great things together for years, standing at whiteboards while I pushed and yelled and played every side of an argument to force her to defend her proposals.
Except one afternoon in the middle of a session, just a regular day, she sat down with actual tears in her eyes and asked me: “Why do you DO this?” She was exhausted and it was clear she had lost confidence in herself. I was honestly taken aback — none of this is personal, and if I didn’t believe she were the best person for this job, we wouldn’t have been there in the first place!
And yes, she “knew” this, but it didn’t matter. It turns out she was doing great work in spite of, not because of, my constant barrage of devil’s advocacy. Or more accurately, the way I was presenting my arguments. Some very small adjustments on my part led directly not just to a happier and more confident colleague, but to faster and better results. ***
And that’s the kicker — adjusting my own behavior and perceptions didn’t just help the other person, it got me more of what I wanted too, without costing me anything. You’d have to be crazy not to make that trade, right? Yet that is exactly what the “anti-woke” crowd pushes every day. Somehow we’ve created a ton of people that are so weak, so scared of anything that challenges themselves or their beliefs, they are actually pushing for the government to protect their fragile egos at their own expense. It’s insane.
The ”alpha male” narrative is not just super-weird, it’s also 100% upside down. What could possibly be weaker than crying “unfair” every time somebody challenges your position? Having a healthy ego by definition should mean you can listen and do a bit of introspection without being butt-hurt. I can be proud of my accomplishments and have a clear-eyed view of my unearned advantages at the same time.
This is true even if, in some incredibly rarified cases, the scales tip a little the other way. If DEI programs make it just a tiny bit harder for a white dude to get into a particular college or job, step up and work a little harder — isn’t that exactly what you’ve been saying to disadvantaged populations for years when the tilt is reversed? Don’t be such a chicken-sh*t.
I’m just really tired of the voice of “personal responsibility” and “strong men” being such a farce. Let’s create a world that works every day to be better and stronger and solve problems — not one that whines and cries and pretends it’s tough by buying a gun and hanging a flag on the truck. Wake up, white guys.
*** I suspect if my spouse reads this she’s going to laugh long and loud, because she taught me this lesson very early in our relationship — yelling in an argument was NOT going to end well. So why did it take so long to translate to work? Human psychology is weird, man.
Way back in 1992, my first task as a new full-time Microsoft hire was to implement language-aware sorting in Works for DOS. It was a great introduction to professional software development at a time when we really had to care about memory and speed and the tradeoffs between them. That doesn’t happen much anymore, but it’s super-fun when it does.
Some ancient history
The earliest personal computers mostly relied on the ASCII standard, which uses seven bits to represent essentially the keys on a typewriter, plus a few “control” characters that encode newlines, tabs, stuff like that. A handy thing about ASCII is that the letters are in numerical order, so you can use simple math to sort things. For example, lowercase “a” through “z” are represented by the numbers 97-122 — bigger numbers sort after smaller ones.
Pretty quickly though, folks remembered that languages beyond English exist, and most of them need different or at least additional characters — e.g., the accented vowels in French, or completely distinct glyphs in Cyrillic. The good news was, most of our computers stored data in eight-bit units. Since ASCII only used seven bits, we could use that leftover bit to squish in another 128 characters. Woot!
Well, sort of woot. First of all, while the ISO-8859-1 standard managed to include most extended Latin characters, there wasn’t enough space to hold all the glyphs in the world. Instead you had to set up your computer with a specific “codepage” designed for your language of choice, and documents created in codepage X could look like gibberish when rendered by a computer running codepage Y. And don’t even get me started on double-byte encodings (the genesis of the once-ubiquitous “Kanji backspace” interview question).
Even worse for 1992 Sean, the letters in the upper ranges of these codepages were decidedly NOT in numerical sort order. My job was to create the smallest possible data structure that would enable Works to sort correctly and quickly using any supported codepage.
The specific implementation I created wasn’t actually that interesting — just a two-shot algorithm that used math for the lower register and a set of super-compressed lookup tables for the upper. What was memorable was how hard I worked to squeeze and shift and mask and torture that lookup data into the tiniest footprint possible.
And it really mattered! In those days the code for Works couldn’t all fit into memory at once. The program shipped on a set of about six or so floppy disks, and a dynamic loader would prompt the user to swap the disks in and out during execution. The more space your feature took up, the more swapping was required. And users hated those interruptions, so we tried really hard to avoid them.
Thanks to the exponential growth of cheap memory and CPU power, issues like this just don’t come up very much anymore. Characters generally take up sixteen big fat bits and nobody even blinks. The horror!
Developers of a certain age (ok, my age) (ok, me) love to talk about how kids today don’t really code, they just search Google for pre-built libraries and slap them together with a bit of Javascript glue. Of course that’s not true — today’s coding problems aren’t easier, they’re just different. But it does feel like we’re losing a bit of the craft of it all, so it’s rewarding when a problem comes along that demands some old school chops. That happened to me the other day, and it was indeed super-fun.
Back to the immune system
My last job before retiring was at Adaptive Biotechnologies, which uses next-generation sequencing to understand what’s going on with the adaptive immune system. The most immediate clinical use of the technology detects early recurrence (MRD) in blood cancers. Dr. Lanny Kirsch is “the guy” at Adaptive (and frankly the world) when it comes to deciphering complicated MRD results — my favorite Adaptive memories are of working with Lanny to help him dig into the biology of it all.
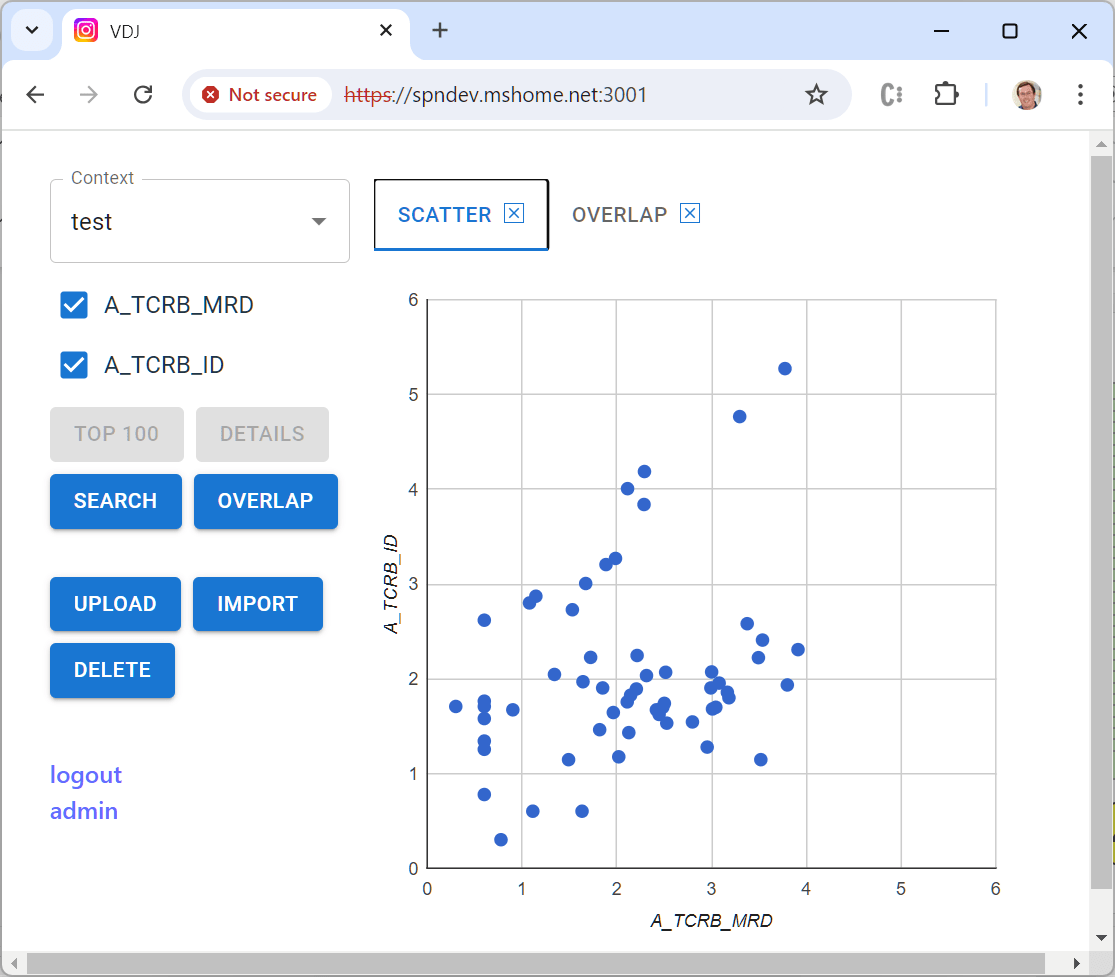
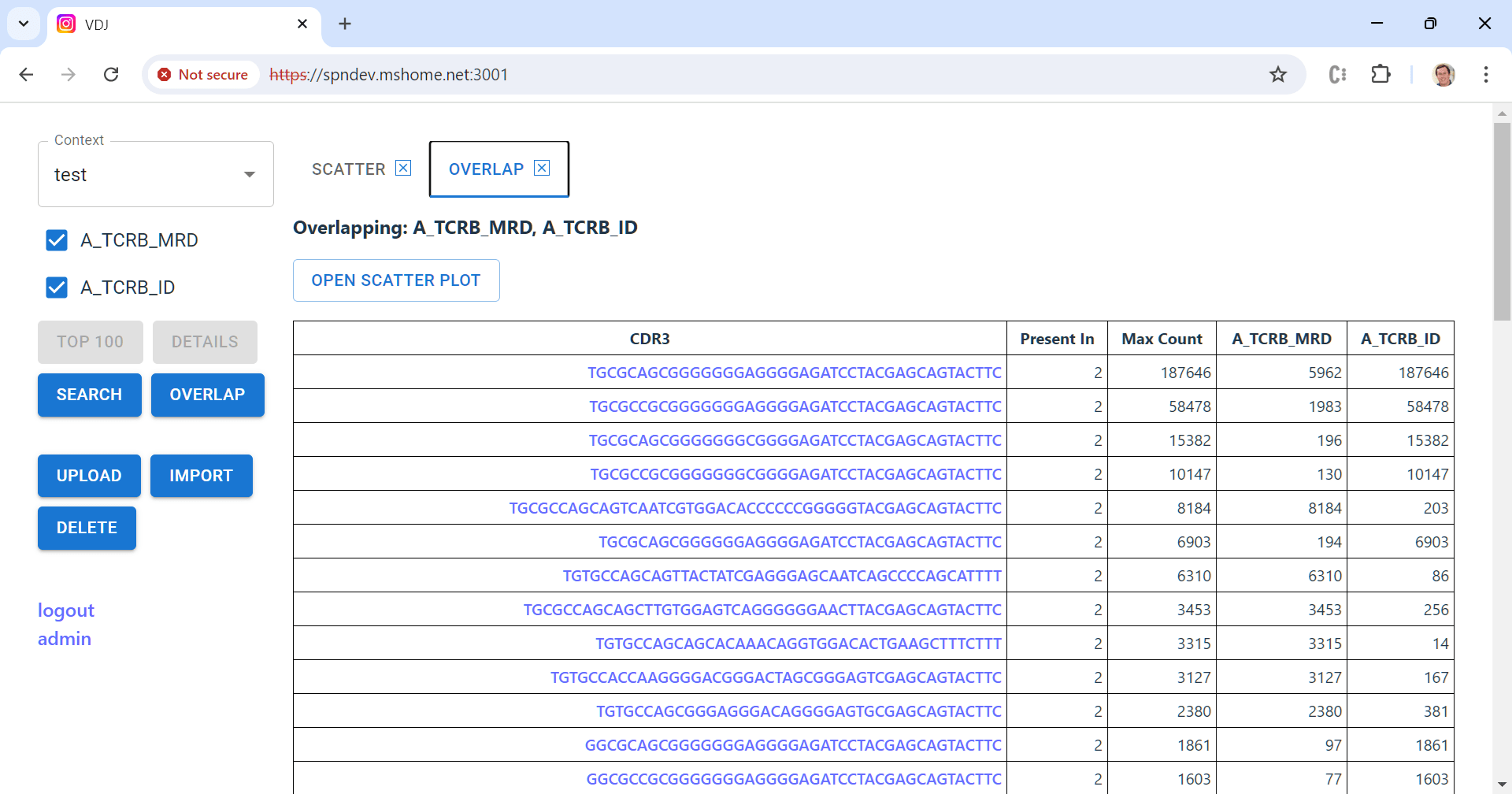
Anyway, even back when I was CTO, Lanny was asking for a visualization tool to help him examine cases. We never got it done then, and a few weeks ago he emailed me “just saying” that it still would sure be helpful. Since (a) I like writing code, and (b) I like Lanny, I decided to give it a shot. The result is an open source tool that I’m hopeful will be useful not just for Lanny, but for anyone in the small but mighty community that works with Adaptive data.
Adaptive’s test creates a laundry list of all of the unique T- or B-cell receptor sequences in a sample of blood or bone marrow. In blood cancers, one of these cells begins to multiply out of control. Post-treatment, detecting even one of these cells can be clinically relevant. Adaptive routinely reports out millions of unique sequences, and with a bunch of metadata per sequence the output files can get pretty huge. Not “LLM” huge, but big enough that working with them in memory gets challenging really quick.
A key feature of the tool is to compute the “overlap” between a set of samples from the same patient — which sequences appear in more than one sample, and at what frequency. This is a challenging computation to do efficiently because you have to compare every sequence in every sample. The best way uses two steps: (1) sort the sequences in each sample, then (2) compare them in order starting from the front. That part of the code is here.
Sorting again!
Of course, this only works if you can sort the sequences in the first place! Not a problem, you say — every modern environment provides built-in, well-optimized sort routines. In some ways these are so convenient they make my teeth itch — one innocent-looking line of streaming sort code can hide wicked performance issues (sorry, old guy again).
But itchy teeth aside, this usually is the best first thought. Sorting in memory is simple, and given the crazy-low cost of RAM, even for really big files it can make perfect sense to just super-size the environment and get ‘er done. But not always. First, in a cloud environment like AWS or Azure, RAM costs aren’t actually crazy-low at all. A 2 CPU / 1GB RAM VM at Azure today runs about $8 per month, while a 32 CPU / 128GB RAM VM is $972! Of course you’re paying for both CPUs and RAM here, so it’s not a perfect comparison, but still, that’s real money. Yeesh.
“Just go bigger” also breaks down in multi-user environments — it may be OK to hog a few gigabytes of RAM for a single sort operation, but multiple concurrent users, all using big memory at the same time, can easily break the bank.
External Merge Sort
All of which — finally — brings me to the punchline for today: external merge sort. This approach caps memory use by leveraging secondary storage for interim results. Only sequential reads and writes to secondary storage are used, so it’s well-suited for spinning disks where seek time matters a lot. We don’t need it very often, but when we do it’s definitely all that. The algorithm works like this:
A fixed-size “chunk” of the input file is read into memory. The data in the chunk are sorted using built-in methods, then written to a temporary disk file. This process is repeated until the entire input file has been chunked, internally sorted and written out. Because there’s never more than one chunk active at a time, its configured size defines the high-water mark of memory usage.
Each pair of temporary files is merged together and written into a new combined temporary file. Because each input is already sorted, this operation requires basically no memory at all; individual entries can be streamed directly from the two inputs into the combined file.
This pairwise-merge process is repeated, using the new combined files as inputs, until only one file remains — the final, fully-sorted result.
There are a few ways we can tweak things to optimize performance in specific scenarios. First and most relevant in the modern world, we can pick a pretty big chunk size. Big enough and some inputs may completely fit in a single chunk — in which case, we can do the whole sort in memory after all!
This turns out to be a really important lesson for contemporary environments: use what you’ve got. It’s a perfect combination for the Adaptive case, where for reasons of cost and biology input size can vary dramatically.
You can also choose to merge more than two temporary files at a time (in fact, you can see this in the overlap code I mentioned earlier). Each merge step re-reads and re-writes data elements, so a larger number here can make a lot of sense.
Because each merge step is completely isolated from the others, the algorithm is also well-suited to multithreading. In my version, each pairwise merge runs in its own worker thread.
Steal this code: LineSorter.java
Note: the rest of this article is just a description of my EMS implementation, useful for working with the code but boring otherwise. Feel free to bail out if that’s not your thing — I hope the first half was worth your time!
I’m fond of the external merge sort implementation I wrote for the Adaptive visualization tool (KeySorter.java). But it makes some assumptions that aren’t particularly reusable, so for the purposes of this article, I rejiggered things a bit as LineSorter.java in the ShutdownHook Toolbox.
Other than a few references to the “Easy” utility class (“easily” removed, ha), you should be able to take this file as-is and drop it into your projects. Or you can just build it as part of the toolbox (you’ll need git and mvn and a semi-recent JDK):
(That last command is just an example that returns a sorted list of all the usernames in your /etc/passwd file. “-s:” tells it to use a colon as field separator, and “-c0 -o0” tells it to sort and output the first field of each line. Use “-?” to see a full list of options in the entrypoint, which includes an option to experiment with chunk size.)
Interfaces make it usable
LineSorter, as you might gues from the name, sorts line-based input. The class uses three interface implementations to work with the contents of each line:
LineParserbreaks each line into two strings: a “Key” (the content used for sorting) and “Output” (the content that will be written to the final output file).
Most typical use cases should be covered by these concrete implementations, but of course you’re free to provide your own LineParser and/or SortItem[Factory] as needed.
More parameters
In addition to these interfaces, LineSorter takes a few other parameters:
An ExecutorServicethat supplies worker theads; take a look here for a simple example that just creates and caches threads as necessary.
HasHeaderRow indicates whether the first line of the input should be treated as headers rather than data.
ReverseSort does the obvious. 😉
LinesPerChunk tunes how big each chunk should be — the default is 500,000 lines which honestly means most files will sort in memory anyways. Match to your environment.
KeySeparator and CommentChar probably don’t need to be changed, but they’re there just in case!
Asynchronicity
The class offers both asynchronous and synchronous versions of the public interfaces:
I have a love/hate relationship with async code — it’s often a must-have to keep things running smoothly, especially for IO-bound operations. But it also can make code really messy, really fast. I try to compromise using function pairs like these. The first is a purely synchronous version – straight up logic, do your job cleanly and well. The second wraps up the first in a CompletableFuture and handles the noise that comes along with that. Actually, the async versions are pretty much boilerplate; maybe I’ll build an interface tht cleans up the copy/paste code. Another task for the queue!
Anyway, I guess that’s it for today — the rest of the implementation is (hopefully) pretty self-explanatory. I really do enjoy writing little bite-sized bits of useful code — once a nerd, always a nerd. Until next time!
Oh wait, one more bit of sorting trivia because I just don’t know how to stop. It turns out that Java’s generic List sort implementation is based on TimSort, a merge sort that takes advantage of existing runs of sorted data in the input (a common real-world occurrence). So if our data is mostly sorted AND fits into a single chunk, our sort will be lightning-fast. You can apply this approach to the initial chunking step of EMS as well, but avoiding the degenerate case gets a bit complicated. OK, that’s really the end this time.
Most non-fiction “idea” books are way, way, way too long. They start with some engaging anecdote in chapter one that sets up the thesis or observation in chapter two. The rest of the book is endless restatement — sometimes with useful supporting information, often not. I assume there is some minimum length that editors require for a “serious” book. Give me a pamphlet any day.
Enlightenment Now is also really long, with a thesis that can be stated pretty succinctly. But the length here has a purpose. Pinker absolutely pummels with data to prove his points — and while it was tough to keep focused on chart number 5,008 of a million, he succeeds.
It’s almost impossible not to be worn down by the inanity of the public sphere; Enlightenment Now offers insight and tools that offer hope to those of us who believe in progress and innovation and the steady improvement of humankind. I’ll try to pick out the high points here, but the full meal deal is worth the effort; highly recommended.
1. Things are pretty amazing
Humans have been around for tens of thousands of years. For most of that time, we bumbled along, slowly improving our lot but largely living hand to mouth, the exception being tiny ruling classes that thrived on the backs of their impoverished people. But for some reason, starting in the late 18th century, pretty much everything started to accelerate for the better.
The obvious thing to do here would be to recount facts from the book, but there are just too many to do it justice. Just a tiny selection:
Since the 1700s, the % of people in extreme poverty has dropped from 90% to 10%.
6% of children die at birth in the poorest parts of the world, down from 33% in the richest.
Catastrophic famine has virtually disappeared from the earth.
Nuclear stockpiles are down 85% from their high in the 80s.
War between countries has become the extreme exception vs. the norm.
Two hundred years ago 1% of world population lived in a democracy. Today, 66% do.
Since the early 1900s, Americans are 96% less likely to die in car accidents, 92% less likely to die in a fire, 90% less likely to drown, 95% less likely to die on the job. We also work 22 hours fewer per week.
Again, this is just a tiny random sample. And the problem with presenting this stuff in bullet form is that it feels counterintuitive and/or naive. After years in Iraq/Afghanistan and Israel/Hamas/Russia/Ukraine, is war really the exception? Should we really be excited about an 85% drop in nuclear arms when 15% is more than enough to destroy civilization? Global averages don’t matter if you’re at the bottom of the scale. And what about other existential threats like climate change or pandemics?
That’s why the book is worth reading. There is an avalanche of good news, including stuff you would never expect, and Pinker backs it up with real data — the narrative is messy and a bit mind-numbing, but he’s convinced me that it’s real.
2. How did this happen?
Things have been improving pretty consistently for hundreds of years, but why? It turns out that the Age of Enlightenment was really quite special. We began to turn away from superstition, and instead applied our brains to understand the world and make it better. We accepted that there is a reality underlying our world; that it is understandable and consistent; and that we can continually improve our understanding to create the circumstances that maximize human flourishing. We became scientists.
Of course there were scientists before the 1700s, and great ones at that. But as a species, we were bound by religion and made-up stories. Those aren’t gone, but by “mostly” accepting that magic isn’t real — that our understanding of the world is limited and often wrong — that we can keep iterating to make it better — and that we can use our knowledge to shape the world through technology, politics, education — we’ve been able to enjoy exponential progress.
There are some interesting warnings tucked in there. It depends on an objective reality, and it accepts that we’ll be wrong a lot. It assumes a more-or-less shared understanding of what “human flourishing” is. There are forces that push back on these and more, but we’ve been able to keep at it for about a quarter of a millennium.
The big takeaway is that, despite it all, the world is working. The United Nations works. Doux commerce works. Nonviolent protest works. The WHO, NIH, and CDC work. The FDA, EPA and international agreements work. Interpol works. Charitable giving works. Education and even Democracy work. None of them perfectly, and not all of them forever. We can / must do better. But still, pretty impressive.
3. So why aren’t we all psyched?
First of all, “better” and even “better in almost every way by huge margins” doesn’t mean great. Millions suffer every day, and the most privileged of us still have legitimate cause to be depressed sometimes. We haven’t solved climate change and Russia is doing their best to screw things up. It’s easy to be overwhelmed by negative trends that, while maybe short-term in the life of the species, easily can encompass our own lifespans. And it’s just human to focus on today’s problems vs. those of twenty years ago, even if they’re smaller by comparison.
Pinker also hypothesizes that at least some increased anxiety in our lives is completely rational. When you don’t know how to read, never leave your village, and have the local priest telling you God has it all figured out, life is seems a lot less complicated. We know more and understand more, so guess what? The world is huge and scary and capricious and certainly doesn’t care about me personally. Yikes.
But even people that say they are personally happy tend to feel (or at least say) that the world is getting worse. While it seems trite to say, it turns out that this “intuition” is strongly reinforced by “the media” interacting with the way our brains have evolved:
Availability: We think things we hear about are common, even though they may not be.
Recency: We heavily weight what we just heard, even if it’s the exception.
Confirmation: Once something is in our head, it holds on for dear life.
Nostalgia: We tend to remember the past as far better than it really was.
There are for sure incredible journalists out there, but writ large “the media” just wants us to watch their ads and buy their content. The things that accomplish that are big, scary, explosive, titillating and sexy, so that’s what gets reported. Random statistical fluctuations turn into “surges” or “concerning trends” or they “signal potential disaster.” We’re told to be angry about everything. Slow news days here in Washington always bring out the stories about Mt Ranier popping off, or the continental plates pulling a Lex Luthor on my house at Whidbey.
Of course I get sucked into this too — and if you cover the whole world and predict disaster every day, you’re going to be right sometimes! It’s hard to know what to do about this; ignoring the news might make you happy but also makes you a lousy citizen. The best I can come up with is to try and limit the “breaking news” popups on my phone and try to read whole articles rather than just scroll headlines. Not easy.
4. So we can just relax, right?
Of course not.
All of the goodness that Pinker catalogs happens because real people are making it happen. They’re recognizing problems, using facts and history and ideas to understand them, designing solutions, trying them out, throwing away the ones that don’t work and improving the ones that do.
This is why life without God has meaning — we’re all part of a great machine that, despite our own innate irrationalities, are helping humanity flourish in the world. Inexorably, hard won, with terrible setbacks. My failures easily outnumber my successes, but I’m still pretty proud of what I’ve created so far (mostly looking at you, A & C).
Enlightenment Nowwas published in January 2019, smack in the middle of the Trump presidency. Given events since then, it seems like the world saw the book and said “Pinker, hold my beer.” Populism, COVID, abortion, human rights, inflation, Ukraine, Hamas — and the risk of more chaos and setbacks if we elect a convicted felon to his second term.
But when I was in high school, my lit teacher told us that Victor Hugo wrote to a friend, “the key is to live as if men were good, while knowing they are not.” I’ve never been able to find the actual quote or source here, but I like it anyways, and will add this twist: “Work like the world will end if you don’t, even though it probably won’t.”
Dory had it right — just keep swimming (and vote for the deep state).